云鹰读书会2021年第17期(总第72期)
2021-10-182021年10月11日上午,南开大学经济学院云鹰读书会在圆阶教室“国际经济与贸易科研训练:实证”课上顺利进行,本次读书会由2018级本科生苏韧和2019级本科生李彦陈,王鹏云展示Ajay K. Agrawal、Joshua S. Gans和Avi Goldfarb的论文PREDICTION, JUDGMENT AND COMPLEXITY: A THEORY OF DECISION MAKING AND ARTIFICIAL INTELLIGENCE,由国际经济贸易系王永进老师、李坤望老师跟进指导。
特别鸣谢
本次云鹰读书会由南开大学国际经济贸易系
系友苏武康博士赞助支持
引入
在本文中,我们的方法是深入研究目前在人工智能(AI)领域正在发生的细节问题。人工智能的最新发展浪潮都涉及到机器学习的进步。这些进步允许自动化和廉价的预测;也就是说,从可用的数据中提供一个感兴趣的变量的预测。
在某些情况下,预测使任务完全自动化——例如,自动驾驶车辆,数据收集、行为和环境预测以及行动的过程都是在没有人参与的情况下进行的。
在其他情况下,预测是一个独立的工具——如图像识别或欺诈检测——它可能导致也可能不会导致机器进一步取代这些工具的人类用户。到目前为止,人类和机器之间的替代主要集中在成本考虑上。机器是否比人类更便宜、更可靠?然而,本文明确地考虑了预测在决策中的作用,并从中考察了在任务中可能与预测相匹配的互补技能。在这方面,我们的重点是我们所说的判断。虽然判断是一个意义广泛的术语,但这里我们用它来指一种非常具体的技能。要了解这一点,请考虑做出一个决定。这个决定涉及到从一个集合中选择一个动作X。该动作的回报(或奖励)由一个函数u(x,θ)定义,其中θ是从一个分布,F(θ)中得出的不确定状态的实现。
假设,在做出决定之前,可以生成一个预测(或信号)s,从而产生一个后验F(ϑ|S)。因此,决策者将解决:
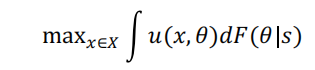
我们首先为我们的假设提供了支持性的证据,即人工智能的近期发展压倒性地影响了预测的成本。然后,我们使用放射学的例子来为理解预测和判断的不同角色提供一个背景。从Bolton and Faure-Grimaud(2009)中汲取灵感,然后我们建立了具有世界两种状态和每个状态行动回报的不确定性的基线模型。我们探讨了在没有任何预测技术的情况下判断的价值,然后在没有判断的情况下预测技术的价值。
我们通过探索预测和判断之间的相互作用来完成对基线模型的讨论,证明只要判断不太困难,预测和判断就是互补的补充。然后,我们将预测质量划分为预测频率和预测精度。随着判断能力的提高,准确性相对于频率变得更加重要。最后,我们研究了潜在状态数量很大的复杂环境。这种环境在自动化、承包和公司边界的经济模型中很常见。我们表明,预测的改进对判断重要性的影响很大程度上取决于预测的改进是否使自动决策成为可能。
人工智能和预测成本
我们认为,人工智能的最新进展是预测技术的进步。最广泛地说,我们将预测定义为获取已知信息来生成新信息的能力。我们的模型强调了对世界状态的预测。
基础模型

![]()
在缺乏了解风险行动的具体回报的情况下,只能根据先验概率作出决定。然后选择安全措施:
![]()
A1 (Safe Default) vR+ (1-v)r≤ S
预测提供了对state的知识。判断的过程提供了对回报功能的知识。因此,判断允许决策者理解如果出现特定状态,哪种行动是最佳的。假设这些知识是在没有成本的情况下获得的(就像它在通常的经济理性假设下所做的那样)。换句话说,决策者拥有在给定状态下的最优行动的知识,然后将选择有风险的行动。
A2 (Judgment Insufficient)max{μR+(1−μ)r,μr+(1−μ)R}≤S
在这个假设下,如果每个state的不同的行动是最优的,并且这是已知的,决策者将不会改变风险行动。当然,这意味着预期的收益是:
![]()
请注意,在没有任何成本的情况下,全面的判断可以提高决策者的预期回报。
判断不是免费的。我们在这里假设这需要时间(尽管这个公式自然会与它需要昂贵的努力的概念相匹配)。假设折扣因子为δ<1。决策者可以花一段时间来确定一个特定状态的最佳行动是什么。如果他们选择对状态应用判断,那么有一个概率,他们将确定该时期的最优行动,并可以根据该判断做出选择。否则,他们可以选择在下一时期对该问题应用判断。
在这一点上,考虑判断一旦应用了意味着什么是有用的。我们在这里做出的最初假设是,一旦做出决定,对回报函数的知识就会贬值。换句话说,应用判断可能会延迟一个决定(这是昂贵的),它可以改进这个决策(这是它的价值),但它不能产生可以应用于其他决策(包括未来的决策)的经验。换句话说,判断的最初概念是思想的应用,而不是经验的收集。实际上,这将我们的检查简化为一个静态模型。然而,在后面的一节中,我们将考虑经验公式,并证明静态模型的大部分见解将延续到动态模型。
下面是整个判断过程,原文比较方便理解:

假设决策者专注于判断的最佳行动(即评估收益)。那么,申请判决的预期折扣收益为:
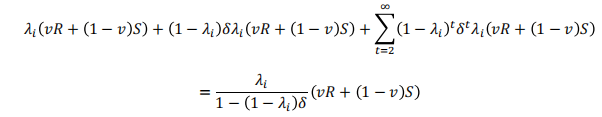
这个计算假定决策者在进行判断之前状态是真的。如果不是这样,那么预期的收益单独是:
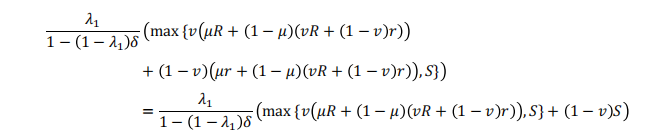
如果只对一个状态进行判断,然后作出决定,这将是需要考虑的相关回报。然而,由于这两个状态都有可能进行判断,因此有几个案例需要考虑。首先,决策者可以按顺序对这两个状态应用判断。在这种情况下,预期回报:
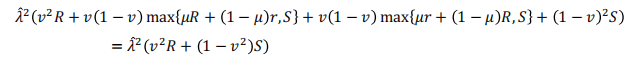
其次,决策者可以应用判断到然后,根据那里的结果应用判决到。如果决策者选择对进行判断,如果的结果是风险行动是最佳的,那么收益将成为
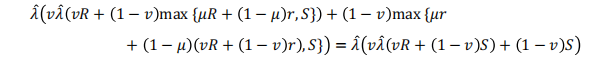
如果的结果是安全行动是最佳的,那么收益将成为
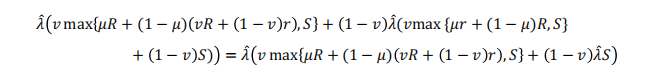
Proposition 1
在假设A1和A2成立的情况下,并且在没有任何关于状态的信号的情况下,(a)判断两种状态,以及(b)在发现在某一状态下首选保守策略后继续进行判断,这两种状态永远不是最佳状态。
证明:注意,在以下情况下,判断两种状态是最佳的:
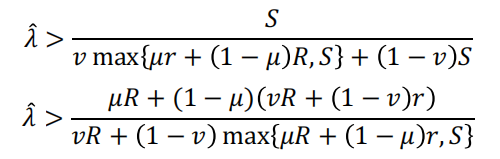
由A2可知,第一个式子可以简化为![]() ,这与前文的假设冲突了。
,这与前文的假设冲突了。
因此,判断两个状态主要取决于判断一个状态,并且只有在该状态下发现风险是最优的情况下才继续探索
关于只有在一个状态发现保守策略更优时才继续进行判断的策略,我们可以将其与对一个状态进行判断然后立即采取行动的回报进行比较:
![]()
这一式子永远也不能成立,所以说(b)永远不会是最优的。
给定命题1,只有两种策略可能是最优的(在没有预测的情况下)。
策略J1
判断适用于一个状态,如果风险行为是最优的,则立即采取该行为;否则,将立即执行默认保守行动。
首先适用判决的状态是最有可能出现的状态。如果μ>1/2,则为状态1。如果:
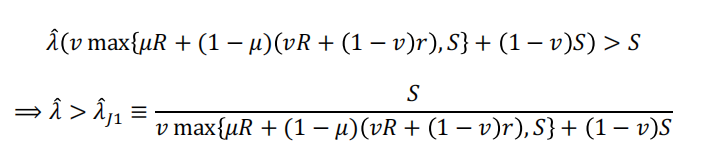
这要求:![]() (否则后式化简将等于1)
(否则后式化简将等于1)
战略J2
判断应用于一个状态,如果风险行为是最优的,则判断应用于下一个状态;否则,将立即执行默认保守行动。
在以下情况下,J2优先于J1:
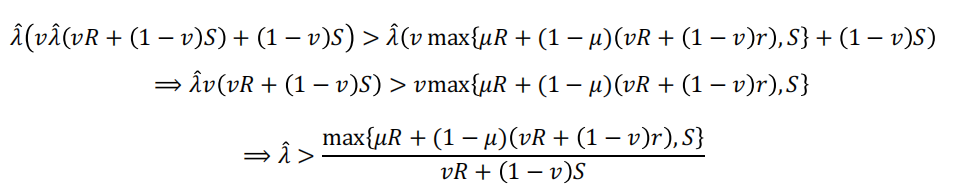
J2也必须优先于产生S回报的保守策略:
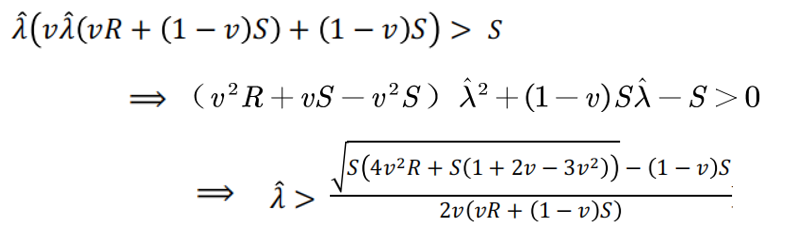
我们可以得到一个小结论:只有在判断效率足够高的情况下,更多的判断才适用。
如果满足以下条件,则可以选择J2:
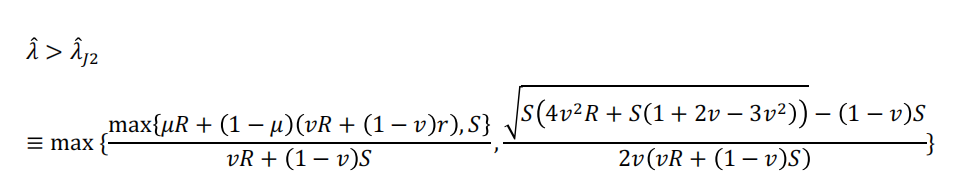
其中,第一项是J2支配J1的临界值,而第二项是J2单独支配J1的临界值;因此,为了使J2达到最佳状态,它必须同时超过这两个值。
还应注意当![]() (其最高可能水平)时,
(其最高可能水平)时,![]()
当时,
足够大时,J2优于J1
位于两者之间时,J1优于J2
足够小时,保守策略占优
当时,
①只要大于,J2就优于J1
②小于,保守策略占优
无判断的预测
假设存在一个人工智能机器,如果部署,它可以在做出决策之前识别状态。
在缺乏预测或判断的情况下,假设A1确保选择安全措施。如果决策者了解该状态,则在以下情况下选择给定状态下的风险行为:
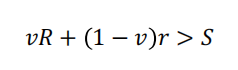
这是与A1冲突的,所以说预期回报是:
![]()
如果没有判断或预测,结果是一样的。
预测与判断相结合
由于判断代价高昂,因此,不浪费时间考虑在一个不会出现的状态可能采取的行动是有益的。在没有预测的情况下,这是不可能的。如果我们收到关于该状态的预测,那么我们就可以对与该状态有关的行为进行专门的判断。有鉴于此,如果决策者是在预测状态后应用判断的决策者,他们的预期贴现回报将是:
![]()
预测和判断都达到最佳的必要条件是:
![]()
其中(这个条件保证了后续探讨预测和判断两者关系的有效)
![]()
Proposition 2-互补还是替代?
我们假设概率为e时,AI产生预测,否则,决策必须在其缺席的情况下做出(仅凭判断)。
Proposition 2
当时,预测和判断是互补品,否则它们是替代品。
证明:
步骤1:证明引理:
![]()
首先,
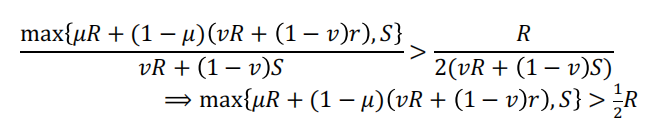
由A2以及μ大于1/2的假设易得以上式子成立。
其次,
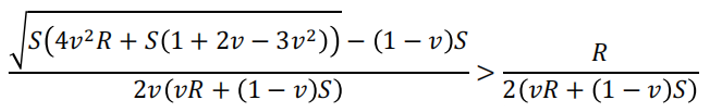
化简后得:
![]()
不等号左边总为正,右边总为负,所以上式始终成立。
步骤2:分情况证明原命题:
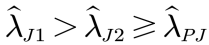 (J1永不占优)
(J1永不占优)
![]() 关于
关于![]() 的混合偏导数
的混合偏导数![]()
![]()
所以此时预测和判断是替代品。
②![]()
![]()
混合偏导数为![]() ,所以此时预测和判断是互补品。
,所以此时预测和判断是互补品。
2)![]()
①![]() ,类似于(1)①,此时预测和判断是替代品
,类似于(1)①,此时预测和判断是替代品
②![]() ,类似于(1)①,此时预测和判断是互补品
,类似于(1)①,此时预测和判断是互补品
③![]()
![]()
=![]()
混合偏导数为![]()
![]()
![]()
![]()
所以混合偏导数大于0,此时预测和判断是互补品。
复杂性
虽然这些结果表明预测和判断是可以替代的,但在某种意义上,预测和判断更自然地是互补的。预测能够实现的是一种状态或有决策。在没有预测的情况下,决策者被迫做出相同的选择,而不管可能出现的状态如何。在缺乏预测的情况下,判断的作用是做出选择。此外,当存在显性(或“接近显性”)选择时,这种选择更容易——也就是说,更可能是最优的。面对复杂性,在没有预测的情况下,判断的价值减少,我们更有可能看到决策者选择平均而言可能比其他人更好的违约行为。
假设现在我们添加一个预测的机器。而在我们的模型中,这样的机器,当它给出一个预测时,可以完美地指示将出现的状态,让我们考虑在复杂情况下可能出现的更方便的替代方案:预测机器可以完美地对某些状态(如果它们出现)发出信号,但是对于其他状态,除了其中一种状态是正确的这一事实之外,不可能做出精确的预测。换言之,预测机有时可以进行精细预测,有时可以进行粗略预测。这里,预测机器的改进意味着机器能够呈现精细预测的状态数量的增加。
考虑一个N状态模型,其中状态I的概率是。假设状态{1,…,m}可以由AI很好地预测,而其余状态则无法区分。假设在无法区分的状态下,应用判断是不值得的,因此最佳选择是安全行动。
假设当预测可用时,判断是值得的,即![]()
在这种情况下,当预测和判断都可用时,预期回报为:
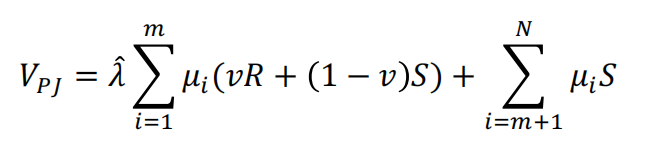
注意,随着m的增加,更好判断的边际值也会增加。
当情况变得更复杂时(即N增加),对于任何给定的i,N的增加将弱地导致N的减少。保持m不变(因此预测机器的质量不会随着世界的复杂性而提高),这将降低预测和判断的价值,因为更大的权重被放在无法预测的状态上;也就是说,假设复杂性的增加不会创建预测可用的状态。因此,复杂性似乎与预测和判断的较低回报有关。换句话说,预测机器的改进意味着m随着N的固定而增加。在这种情况下,当对预测可用的状态施加更大的权重时,判断的回报会增加。
自动化
关于自动化的文献有时是人工智能的同义词。这是因为人工智能可以为能够在开放环境中操作的新型机器人提供动力,这要归功于机器学习。正是这些开放环境中的预测使得环境灵活的资本设备(如自动汽车)得以出现。请注意,这意味着随着AI的改进,更复杂环境中的任务可以由机器处理。最近人工智能的发展都与预测有关。这意味着自动化资本可以转移到更复杂的环境中。当状态无法预测时,所选择的操作更有可能是默认值或执行的启发式结果。许多人认为,对于更复杂的任务,人类相对于机器具有相对优势。然而,这一点并不明显。
如果已知应使用特定的默认值或启发式值,则可以对机器进行编程以执行此操作。在这方面,最复杂的任务——正是因为在状态预测粗糙的情况下,人们对如何采取更好的行动知之甚少——可能更容易而不是更少地实现自动化。想象一下,状态是按减少的可能性排序的:
![]()
①由于最低指数状态经常出现,因此有关于每种状态的最佳操作的知识,因此可以对它们进行编程,由机器处理。
最高索引状态类似,因为无法确定最佳操作,也可以编程。
中间状态出现的频率较低,但并非不常见,如果存在可靠的预测,那么当这些状态出现时,人类可以运用判断来处理这些状态。
回报为:
![]()
其中,任务1到k使用预测实现自动化,因为有关于最佳操作的知识。如果这是任务与机器和人的匹配,那么就根本不清楚复杂性的增加是否与更多或更少的人力就业相关。这就是说,自动化文献中的问题不是“复杂任务”这个术语的微妙之处,而是随着人工智能变得越来越普遍,可能出现机器代替人的情况。如上所述,AI的增加增加了m。在这一边缘,人类能够进入边缘任务,因为有一台预测机器可用,所以在这些情况下使用判断来执行状态或有决策。虽然人工智能不一定会导致更多的常规任务由机器处理,但它可能会创造经济条件,从而实现这一目标。
承包
承包与编程有很大的共同点。
Jean Tirole(2009):合同各方(买方、卖方)最初利用可用的设计,可能是行业标准。该设计或合同是现有知识下的最佳合同。举一个简单的例子,石油价格上涨的可能性是完全可以预见的,这意味着合同应在其上建立索引,但这并不意味着双方将考虑这种可能性并相应地对合同价格进行索引。如果人工智能可用,那么在书面合同中,由于精细的状态预测是可能的,因此有可能产生认知成本,以确定这些状态出现时的意外情况。
Herbert Simon(1951):雇佣合同与其他合同的不同正是因为通常无法指定在什么情况下应该执行什么操作。因此,这些合同通常分配不同的决策权。
Baker, Gibbons and Murphy(1999):随着预测机器的改进和更多的人的判断是最优的,那么这种判断将应用于客观契约度量之外——包括客观绩效度量。如果我们不得不推测,这将有利于更主观的绩效过程,包括关系契约。
企业边界
假设是买方(B)从所做的决定中获得价值,即风险或安全行为的回报(视情况而定)。为了让事情变得简单,我们假设![]() ,对于所有i
,对于所有i
![]()
我们假设任务由卖方承担。任务{1,…,k}和{m+1,…,N)可以签订合同,而中间任务要求卖方进行判断。我们假设提供判断的成本是一个非递减凸函数。因此,如果出现一个中间状态,买方可以选择给卖方一个固定价格合同(不承担任何费用)或成本加成合同(承担所有费用)。
根据Tadelis(2002),我们假设卖方市场具有竞争性,因此所有盈余都归买方所有。在这种情况下,买方回报为:
![]()
卖方回报:
![]()
![]() 合同价格,对于固定价格合同,z为0,对于成本加成合同,z为1。注意,只有成本加成合同,卖方才行使任何判断。因此,买方选择成本加成而非固定价格合同,前提是:
合同价格,对于固定价格合同,z为0,对于成本加成合同,z为1。注意,只有成本加成合同,卖方才行使任何判断。因此,买方选择成本加成而非固定价格合同,前提是:
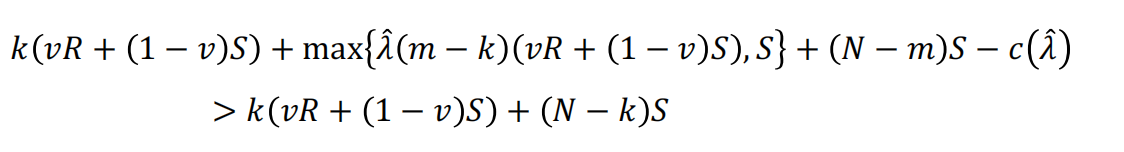
很容易看出,随着m的上升(即预测变得更便宜),更可能选择成本加成合同。也就是说,当预测变得更加丰富时,激励就会下降。
现在我们可以考虑整合的影响。我们假设买方可以选择自己做决定,但成本较高。
也就是![]() ,其中I表示积分。
,其中I表示积分。
我们也假设![]() 。在整合下,买方的价值为:
。在整合下,买方的价值为:
![]()
在这种情况下,![]() 最大化买方收益。有鉴于此,可以很容易地看出,随着收入的减少,一体化的回报率也在上升。
最大化买方收益。有鉴于此,可以很容易地看出,随着收入的减少,一体化的回报率也在上升。
相比之下,请注意,随着k的增加,成本加成合同的激励减少,整合的回报下降。因此,更多的预测机器允许在合同中放置意外事件(m-k越大),卖方激励的力度就越大,整合的可能性就越大。
预测机器的影响将取决于它们是否导致可以以状态相关方式(k)自动执行操作的状态数增加,相对于已知状态但无法自动执行操作的状态数增加(m)。如果是前者,那么随着预测机器的兴起,我们将看到更多的纵向一体化。如果是后者,我们会看到更少。这种差异是由于需要更多的资金。当m-k上升时,垂直整合案例中的昂贵判决。
总结
在本文中,我们探讨了机器学习技术的最新改进带来的后果,这些改进推动了人工智能更广泛的领域。特别是,我们认为机器执行心理任务的能力的这些进步是由机器预测的改进推动的。为了理解机器预测的改进将如何影响决策,分析模型的收益是如何产生的是很重要的。我们将学习收益的过程称为“判断”。我们表明,预测和判断通常是互补的,只要判断不是太难。更好的判断意味着与更频繁的预测相比,更准确的预测是有价值的。在存在复杂性的情况下,改进预测对判断价值的影响取决于改进预测是否会导致自动决策。复杂性是关键自动化、合同和企业边界方面的经济研究。
这方面的研究有许多方向可以进行:
①这篇论文没有明确地为预测的形式建模——包括哪些措施可能是决策的基础。实际上,这是一个重要的设计变量,影响预测和决策的准确性。
②这篇论文将判断视为一种人类主导的活动。然而,我们已经注意到,它可以被编码,但没有明确说明发生这种情况的过程。
③这是一个单代理模型。在博弈论的环境中,当判断和预测都受到其他主体的行为和决策的影响时,探索它们是如何混合的将是一件有趣的事情。
下期预告
时间:2021年10月18日上午 8:55-11;40
地点:南开大学经济学院圆阶305
论文:Finding Needles in Haystacks:Artifi cial Intelligence and Recombinant Growth
请期待!
文稿:苏韧 李彦陈 王鹏云
编辑:刘书渊 刘东辰
审校:王永进