云鹰读书会2023第25期(总第152期)
2023-06-042023年5月5日下午,南开大学经济学院云鹰读书会在圆阶305教室“数字经济与贸易科研训练:理论”课堂上顺利进行,本次读书会由2021级本科生薛靖羲、彭睿同学展示Lin William Cong、Danxia Xie and Longtian Zhang的发表在Management Science论文“Knowledge Accumulation, Privacy, and Growth in a Data Economy”, 2021,由国际经济贸易系 何秋谷 老师跟进指导,助教郑佳豪提供答疑。
特别鸣谢
本次云鹰读书会由南开大学国际经济贸易系
系友苏武康博士赞助支持
00|摘要
本文建立了一个内生增长模型:其中,消费者生成的数据是知识积累的新的关键因素。消费者在提供数据进行牟利和潜在被侵犯隐私的风险之间取得平衡。中间品厂商利用数据进行创新,并为最终的商品生产做出贡献,从而推动经济增长。数据是动态非竞争性的,具有灵活的所有权,而它们的生产是内生的,依赖于政策。尽管去中心化经济的增长速度可以与平衡增长路径上的社会最优增长速度相同(但水平不同),但研发部门存在劳动力就业不足和数据过度使用的问题——可以通过补贴创新者而不是直接的数据监管来缓解低效率。随着数据经济的出现和成熟,消费者的数据提供在过渡积累后内生下降,缓解了长期的对隐私的担忧,但预示着需要干预的初始增长陷阱。
关键词:大数据,数据所有权,内生增长,创新,非竞争性,隐私监管

01|介绍
数据不仅有助于生产新产品和服务,还可用于研发和知识创造,从而提高生产效率。数据的伴随生产生成、动态非竞争性和灵活所有权将其与劳动力和资本这样的传统要素区分开来,这对劳动力市场配置和政策有影响。与此同时,大数据应用的激增往往以牺牲消费者隐私为代价,并与歧视和滥用有关。我们对数据使用或误用、数字基础设施和隐私监管如何影响知识积累和动态经济的增长知之甚少,而在动态经济中,数据恰恰是新的关键驱动力。
因此为了填补这一空白,本文在Romer(1990)的基础上开发了数据经济的内生增长模型。本文的关键创新在于:消费者数据增加了研发和知识积累。同时,数据是经济活动的副产品,具有潜在的隐私问题,这与劳动力或资本等其他输入因素不同,因为增长可以内生反馈到数据生成。在基准模型中,消费者在意识到潜在的信息泄露和滥用的情况下,选择向中间品生产企业出售不同数量的数据。创新的中间品生产企业利用原始数据进行研究,为最终的商品生产做出贡献。具体来说,数据被转换为中间产品(包括信息产品),这是其他模型所没有的特征。数据可以通过知识积累产生溢出效应,随着时间的推移,当数据被交易并被多方使用时,这种溢出效应在极低的复制成本下会进一步增强。这些效果会由于数据隐私侵犯问题而减弱。
文章表明,去中心化经济体的增长速度与平衡增长路径(BGP)上的社会最优增长速度相同。但由于研发部门的就业不足和数据过度使用,社会福利和消费者盈余较低。中间产品生产中的垄断性加价导致研发中的劳动力挤出(Jones 1995),然后生产商通过更积极地利用数据来补偿研发中劳动力的就业不足。在研发部门中的数据使用对劳动力群体的挤出达到了社会过度水平。因此,研发部门对劳动力和数据的使用可能会与社会计划者解决方案中的劳动力和数据使用有很大差异,尤其是在BGP的初始阶段。
本文模型表明:相比于对数据过度使用征税,补贴研发工资或中间生产者能更有效地缓解低下的社会效率。此外,由于数据扩大了创新的可能性边界,这表现出规模回报递减,历史数据使用减少了未来数据使用的好处,从长远来看,可能导致人均数据提供量下降。
随着经济向稳态的增长模式过渡,消费者提供的数据可能会在下降之前经历加速增长。重要的是,初始阶段的低增长可能会限制数据的生成,即使在社会计划者的解决方案中也是如此,这会进一步推迟向高增长阶段的过渡——这是一种增长陷阱。对数字基础设施发展给予外国援助等干预措施,可以帮助摆脱陷阱,但是数据生成能力的约束仍然会限制数据的生成,比如,当经济活动转化为较少的数据量时。
02|文献综述
本文主要为新兴的信息和数据经济领域做出了贡献。相比于早期关于信息的社会价值、销售和产权的研究(例如,Hirshleifer 1971,Admati和Pfleiderer 1990,Murphy 1996),最近的研究集中在将数字信息与隐私问题联系起来(例如,Akcura和Srinivasan 2005,Casadesus Masanell和Hervas Drane 2015),或数据的非竞争性与竞争(例如,Ichihashi 2020a,Easley等人2019)。本文的不同之处在于,是第一个将数据使用与知识积累、内生增长与隐私忧虑联系起来的研究。此外,本文的模型补充了从微观基础数据层面对隐私问题的研究(例如,Ichihashi 2020b,Liu 等人2020),与美国和世界各地关于数据经济规模与监管、隐私问题和劳动力份额下降的相关性的经验模型大体一致(Karababounis和Neiman 2014,Tang2019,Abis和Veldkamp 2020,Barkai 2020,Liao et al. 2020)
因此,我们的理论增加了关于经济增长的大量文献,特别是最近的研究,通过允许数据直接进入生产,将数据嵌入增长模型。例如,Jones和Tonetti(2020)强调了由于数据的非竞争性和将数据产权赋予消费者,导致数据的利用不足;Farboodi和Veldkamp(2020)强调数据在长期增长中回报有限。本文补充了Jones和Tonetti(2020),允许数据在半内生增长模型中促进知识积累(Jones1995,2016),并参考Stokey(1998)和Acemoglu et al.(2012)的研究,考虑消费者的数据隐私问题。通过与Farboodi和Veldkamp(2020)不同的机制,本文还发现数据在长期内发挥的作用有限。
03|模型构建
3.1 模型假定
本文模型在以下六点前提假设的基础上展开:
1.经济体由消费者、最终品生产商、中间品生产商组成
2.消费者在每个时期都会消费最终品,同时在消费的过程中产生数据。数据可以被消费者出售
3.最终品生产商使用劳动力和中间品进行生产,且最终产品受到中间品种类和质量的影响
4.中间品生产商可以使用数据进行研发创新,提高中间品的质量;中间品生产商之间存在垄断竞争
5.人口以固定增长率 n 增长,每人提供一单位劳动力用于最终品生产或中间品研发
假定时间连续且无限
3.2 代表性消费者

3.3 最终厂商


3.4 中间品厂商

3.5 均衡的定义
3.6 数据要素的区别特征
尽管数据如何进入中间产品生产函数的函数形式与研发劳动力的函数形式相似,但数据在经济增长中的作用与劳动力或资本有根本不同。在着手求解模型之前,有必要澄清数据的区别特征。数据要素的主要区别特征可以概括为以下三点:
1.内生变化:数据是由消费内生的, 消费本身就是内生的并取决于知识积累中的数据使用
2.动态非竞争:只有潜在的中间生产商需要在每个时期使用原始数据,进入者和在职者都从相同的数据中受益,而不会产生高昂的复制成本
3.灵活的数据所有权:数据可以归公司所有,但劳动力不能
04|平衡增长路径上的数据经济
我们首先沿着平衡增长路径求解模型,该路径要求模型内所有变量都以相同的恒定速率增长——这是文献所关注的转换变量的稳定状态。该部分中,本文确定低效的数据过度使用和研发劳动力提供不足的问题,探索政策补救措施,并讨论了数据非竞争和所有权的含义。
4.1 去中心化经济中的增长率和劳动力份额

4.2 社会计划者解决方案下的增长率和劳动力份额


4.3 去中心化经济中的错误分配和数据过度使用

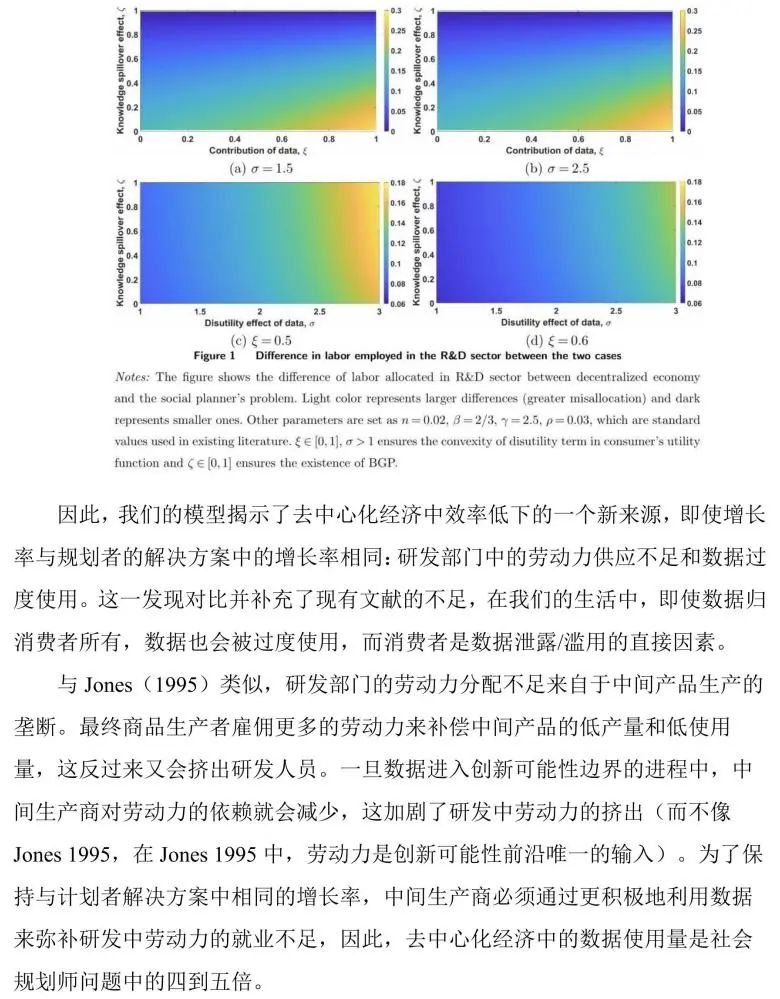
4.4 数据生成和监管政策
与特定于研发领域的劳动力不同,数据的生产是由消费内生的,消费本身也是内生的。大量的数据带来了多样性创新的增加,这反过来又刺激了消费,从而进一步放宽了数据生成的限制。当涉及到劳动力或资本这类要素时,这种关系是不存在的,人口规模或资本的增长往往是外生给定的。
我们在本节中的讨论仅限于在社会计划者的BGP解决方案中,保持增长率的政策干预。本文发现,对数据使用征税改变了过渡动态,但无法使去中心化经济中的均衡分配更接近社会计划者的解决方案,因为它并不能解决研发领域的劳动力就业不足问题,只会在经济最终回到BGP路径初期之前,减缓经济发展。然而,补贴研发部门的劳动工资率,或从利润角度补贴中间生产者被证明是有效的。
数据价格是由中间生产者和消费者决定的。消费者对消费和数据提供的共同决定意味着他们关心数据提供的增长率,而不是水平,如(5)所示。从某种意义上说,对数据购买征收的直接税与数据提供脱钩,因此不会改变均衡的劳动力份额。如果对数据征税,消费者会减少数据的提供,但创新者仍然会使用已有的的数据来创造新产品,因为他们不需要支付数据的边际成本。
l 数据征税会降低消费者提供数据的激励,从而减少数据的供给和创新的需求
l 数据征税会增加中间产品生产者使用数据的成本,从而降低创新的效率和经济的增长
l 数据征税会改变数据的相对价格,从而导致资源配置的扭曲和福利的损失
因此,数据的过度使用与劳动力的分配不均无法得到改善。
而补贴可以提高创新者的收益,从而激励他们增加研发劳动力的投入。这样,创新者就可以用更少的数据来生产更多的新产品,从而降低数据的需求。补贴也可以提高经济增长率,因为它可以促进知识积累和生产效率的提高。因此,补贴可以改善数据的过度使用与劳动力的分配不均。
这一部分研究结果具有重要的政策意义,因为目前的争论集中在隐私法规上,隐私法规对数据经济的增长有决定性的影响。本文展示了研发创新与数据使用的增加之间的关系,以及劳动力市场政策如何有效减少过度使用数据以提高社会福利。
4.5 历史数据和动态数据非竞争
到目前为止,本文强调的数据的一个独特而重要的特性是:动态非竞争。除了在基线模型中通过中间商品的参数设定来隐含表现外,我们现在通过明确建模历史数据的交易和相关的创造性破坏,来扩展我们对动态非竞争的讨论。具体而言,我们现在假设

4.6 数据所有权

05|转移动态:数值分析
数据经济向BGP的转移动态也揭示了一种独特的模式。从前文分析中,我们知道,即使没有限制数据使用的法规,随着经济的增长,数据使用量也可能下降,这缓解了对数据隐私的担忧。与此同时,对于初始增长最小的数据经济体来说,数据生成这一过程表明,如果没有任何改善数字基础设施,或放松隐私监管的干预,它们可能会长期陷入低增长状态。
5.1 方法与校准
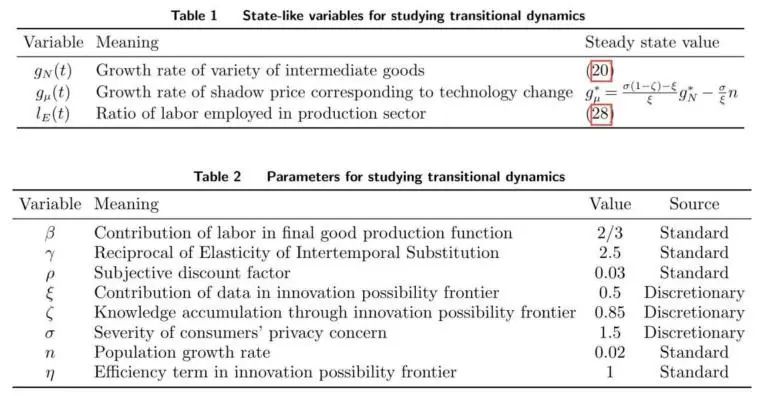
与Jones(2016)类似,出于可操作性的考虑,本文在本次数值训练中重点讨论了社会计划者的解决方案。如果政府实施政策,平衡隐私的保护和增长,比如前面提到的补贴计划,就会出现后文图中的情况。这一分析不是为了复制任何国家的数据而设计的校准,最好将其视为本文理论框架中可能存在的基本转移动态的说明。本文在附录中推导了一个描述规划者经济动态的微分方程组,它们包括对数据生成的约束(3)和三个类似状态的变量,其解释和稳态值如下表所示。可以从中导出其他变量。我们使用“Reverse Shooting”(Judd 1998)方法求解微分方程组。表2提供了参数化的总结。
5.2 结果与讨论
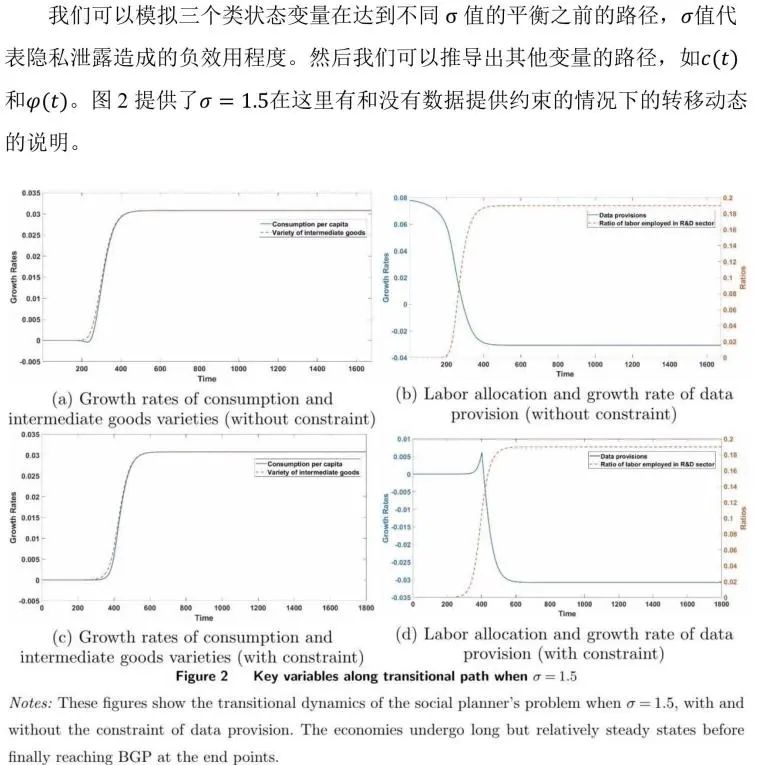
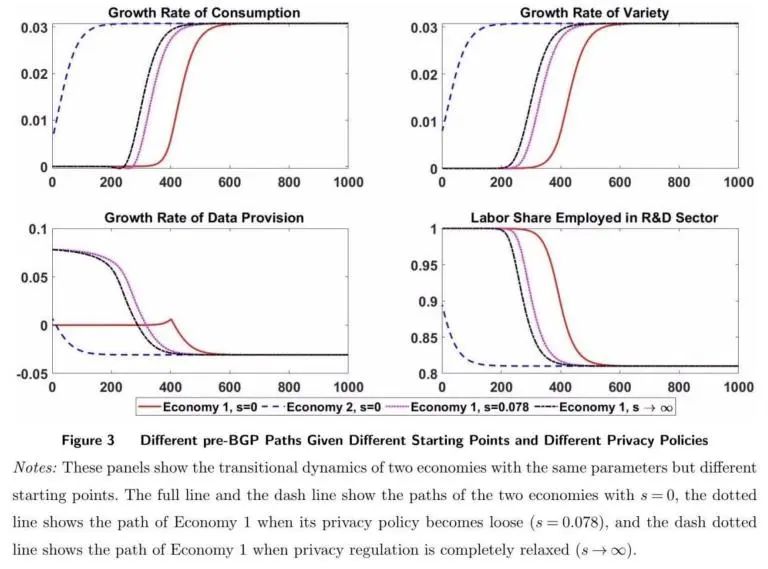
出现了几种稳健的模式。正如(a)和(c)所示,无论经济在BGP之前从哪里开始,消费和品种的增长率都会达到稳定状态,一旦经济达到非平稳增长(足够远离零),就会相对较快地发生转变。此外,如(b)和(d)所示,在BGP中,数据提供的增长率从正下降到负。对于一个从低增长开始的经济体来说,为各种中间产品的积累提供的数据迅速增加,这有助于最终商品的生产和消费增长。沿着这条转移路径,劳动力从生产部门转移到研发部门,这反映了劳动力是如何被用来补偿不断减少的数据供应的。
在图(a)中,与品种的增长率不同,在不受数据提供限制的情况下,消费增长率在上升到正增长率之前经历了一段时间的负增长。这种暂时的负增长在文献中很常见(Brockand-Taylor,2010),表明在向高BGP增长进行调整之初,劳动力从生产部门迁出,这导致了产量和消费的下降。
但数据是唯一的,因为经济活动限制了它们的供应,正如(d)中表现的,数据提供在时间0到400之间具有约束力。暂时的负增长没有出现,因为由于数据提供的减少(导致增长率下降),将劳动力从生产中转移出来的成本没有以前那么高。
5.3 增长陷阱和隐私问题的影响
比较有数据提供约束和没有数据提供约束的情况,我们发现约束(3)适用于初始增长率较低的经济体。人均数据贡献也比没有限制的情况要低得多。本文注意到,对于一个以接近零的增长率开始的经济体来说,它需要近200个额外的时间段(年)才能达到BGP。即使在达到BGP增长后,由于加速增长的延迟,经济产出也可能大幅下降。经济学直觉很简单:最初的低增长限制了数据的生成,这对增长产生了负面反馈,因为数据构成了创新的输入因素,而创新又具有良好的多样性。
提高初始增长率的干预措施对于摆脱这种增长陷阱至关重要。与此同时,我们应该注意到,社会计划者的问题是国家层面的。因此,放松数据提供限制的干预(3)更多地是在国际层面,例如,世界银行、国际货币基金组织或欧盟其他国家为改善数字基础设施和数据收集/存储效率或共享专业知识而采取的行动,这些都有所放松(3)。此外,如果社会计划者经济中的知识积累、隐私和增长最初被预算/现金严格约束,无法改善数据基础设施,外国补贴可能有助于暂时放松约束。
当各国拥有不同的人口增长和不同的技术转让和溢出时,就会出现互联网和人工智能等全球技术创新浪潮。这可能导致截然不同的转移动态。数据约束的紧密性不会影响BGP的增长率,但会影响转移动态。例如,当数据经济出现时,美国和欧洲正处于同一发展阶段,但隐私保护方面的差异(差异)使它们走上了不同的道路,在不同的时间达到BGP。


06|结论
文章在大数据和数字经济兴起的背景下建立了一种内生增长模式。在平衡增长路径下,去中心化经济的增长速度与社会最优分配的增长速度相同,但去中心化经济仍然存在数据被低效率地过度使用、研发人员不足的问题。
由于潜在的信息泄露和隐私侵犯,消费者得不到充分补偿而遭受损失。当消费者拥有数据时,长期下数据隐私问题会得到缓解,因为数据的使用最终会减少。然而,在数据经济中,初期增长率较低的欠发达经济体可能面临一种新形式的贫困陷阱,需要进行干预。
在创造新品种的中间产品的过程中,文章首次将数据视为除劳动力之外的一个输入因素,从而推动最终产品的生产和长期增长。文章强调数据是经济活动的副产品,具有动态非竞争和灵活所有权等特点。为了便于处理,文章聚焦在关键部分,必然会忽略数据经济的某些方面,如最终产品差异化。因此,文章的发现应该被视为一阶基准结果,而不是既定结论。
参考文献
[1] Cong, Lin William, Danxia Xie, and Longtian Zhang. Knowledge accumulation, privacy, and growth in a data economy. Management Science 67.10 (2021): 6480-6492.
下期预告
时间:2023年5月12日下午18:30-21:05
地点:南开大学八里台校区经济学院圆阶305教室
论文:
Farboodi M, Veldkamp L. A growth model of the data economy[J]. NBER working paper, 2021 (w28427).
文稿:薛靖羲 彭睿
编辑:冯双婷 程一然
审校:何秋谷
2023年6月4日