云鹰读书会2023第26期(总第153期)
2023-06-122023年5月19日下午,南开大学经济学院云鹰读书会在圆阶305教室“数字经济与贸易科研训练:理论”课堂上顺利进行,本次读书会由2021级本科生郑烨佟、罗依璠同学展示Simona Abis、Laura Veldkamp的发表在the Review of Financial Studies的2021工作论文版本“The Changing Economics of Knowledge Production”,由国际经济贸易系何秋谷老师跟进指导,助教郑佳豪提供答疑。
特别鸣谢
本次云鹰读书会由南开大学国际经济贸易系
系友苏武康博士赞助支持
摘要
大数据技术改变了数据和人类劳动结合创造知识的方式。这是一次普通的技术进步还是一场数据革命?利用投资管理部门的招聘和工资数据,我们展示了如何估计公司的数据积累和其知识生产函数。了解生产函数实际发生的变化,能让我们明白新的、大数据技术在产出、要素份额和收入分配方面带来了可能的长期变化。利用投资管理行业的数据,本文结果表明,知识相关工作的劳动收入份额可能从29%下降到21%。这种变化与大数据技术相关,是工业革命带来的变化幅度的三分之二。
目录
一、引言
二、生产函数模型
2.1 生产函数
2.2 数据管理和数据存储
2.3均衡
2.4 模型假设的讨论
2.5 最优的公司雇佣和工资
三、数据和估计
3.1 选择投资管理行业
3.2 劳动力需求
3.3 累计雇佣以得到劳动力
3.4 累计数据管理以得到结构化数据存量
3.5 工资
3.6 数据折旧
3.7 估计生产函数
四、估计结果
4.1 比较从工业化到知识生产的变化
4.2 数据正在取代劳动力吗
4.3 估计数据的价值
五、结论
一、引言
机器学习、人工智能、大数据技术减少了人类在产生知识时所投入的鉴别有用知识的精力,这究竟是一次寻常的创新,还是一场变革性的创新?经济学家将工业化建模成一种生产技术的变化:从一种资本回报显著减少的技术,转向至一种资本回报递减较少的技术。因此,工业革命的规模可以被理解为支配收益递减的生产参数变化的幅度。同样的统计方法可以估计新的大数据技术对知识生产的影响。衡量大数据技术的采用在多大程度上改变了数据的收益递减,并将其与工业革命期间发生的生产函数变化进行比较,可以告诉我们这是一次常见的创新还是下一场革命。
Jones和Tonetti等(2020)在研究数据在经济增长过程中的作用时和我们基于模型的方法基本一致,但将数据和知识直接等同起来,而本研究解释了原始数据是如何转化为有价值的、能提高产出的知识的。
许多工作论文都是用劳动力市场数据来调查机器学习和人工智能是如何影响劳动力需求的,例如,Acemoglu和Restrepo(2018)确定了更容易接触到机器学习相关技术的行业,并且报告了这些行业中由于机器学习技术的应用有哪些工作岗位正在增加或减少;Agrawal和Gans等(2017)认为,机器学习很可能是一种通用技术;Kogan和Papanikolaou等(2021)的研究则运用了一种类似本文的测量方法估计了新大数据技术对相关技术人员的雇佣和收入风险的影响。
本文关注技术如何影响知识生产,所以需要使用一种不同的结构性方法,关于自动化和机器人技术的文献也提出了关于物理产品生产的类似问题(Berg和Buffie等,2018)。其他人则研究了在提供信贷(Fuster等,2018)、股权分析(Grenna等,2018,)或更普遍的深度学习(Brynjolfsson等,2017)中采用人工智能技术后的生产率提高或者潜在的歧视成本,这些也与知识生产如何变化的问题不同。《货币经济学》则探讨了机器人和劳动者之间的替代弹性。
此外,测量数据及其价值是对估计无形资产价值工作的补充(Crouzet等,2020),但前人研究目标是分解企业的价值来源,而本文感兴趣的是同一家公司内使用的两种技术有多大不同,所以需要不同的方法。
文章的第二部分建立了一个三方程模型,这是估计的基础,并且推导了我们用于从数据推断参数的最优条件;第三部分描述了数据的获取,以及我们如何使用它来组装与模型中对象对应的变量;第四部分介绍了估计结果,探讨了就业、工资和跨公司的一致性如何决定我们的估计参数,同时还估计了公司数据存量的价值;第五部分是总结。
二、生产函数模型
2.1 生产函数

2.2 数据管理和数据存储

2.3 均衡

2.4 模型假设的讨论

2.5 最优的公司雇佣和工资

三、数据和估计
3.1 选择投资管理行业

3.2 劳动力需求
3.3 累计雇佣以得到劳动力
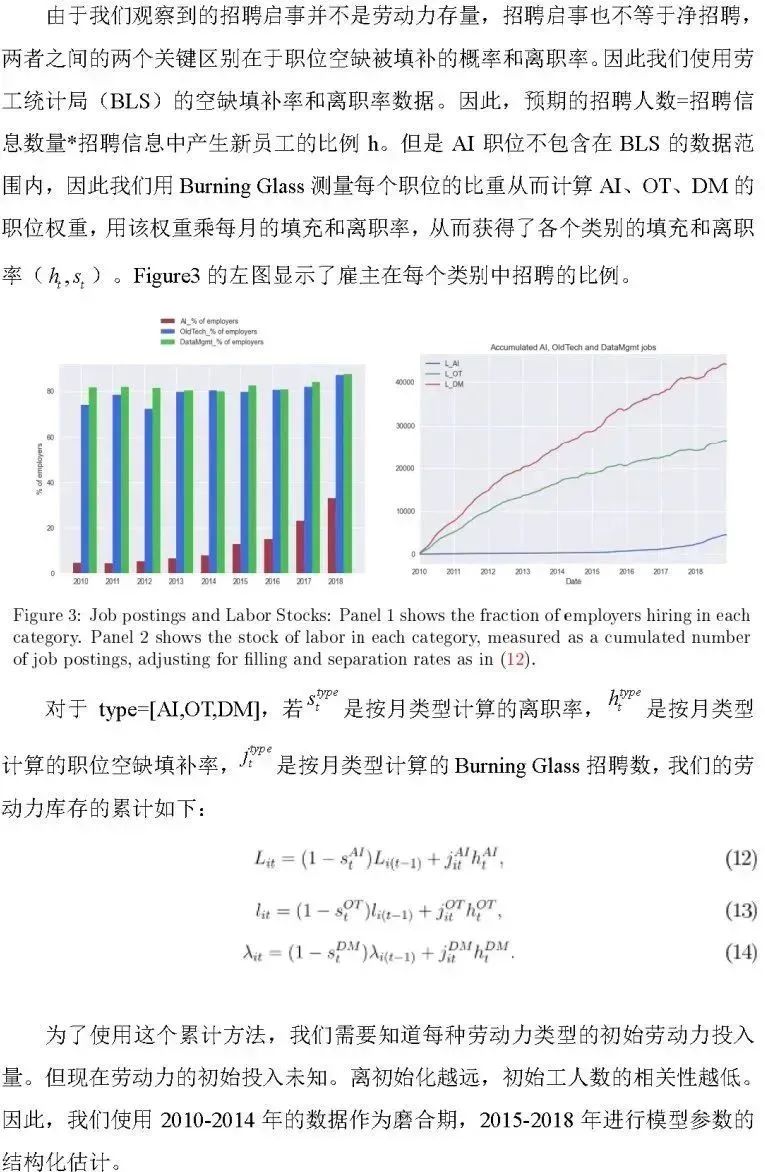
3.4 累计数据管理以得到结构化数据存量

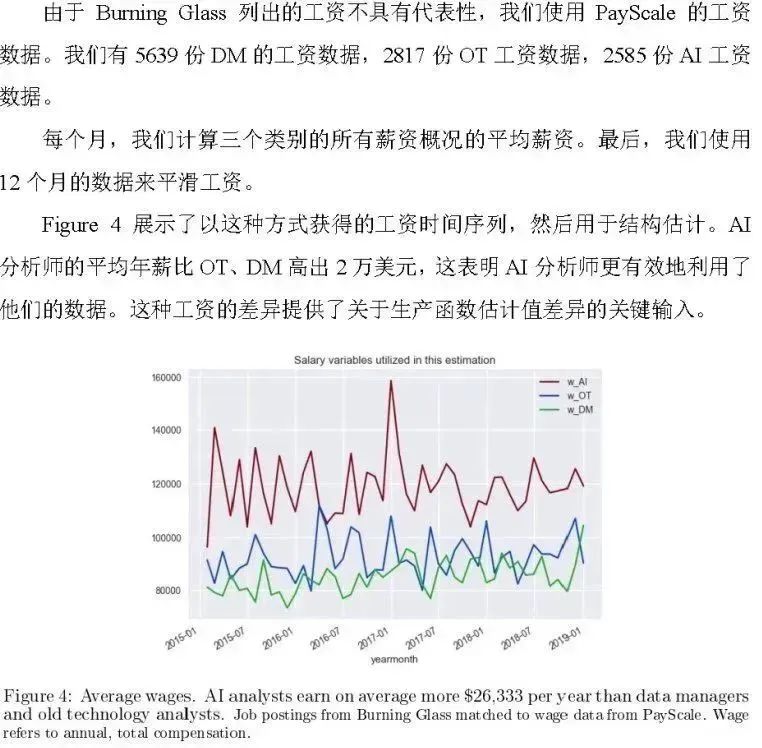
3.5 工资
3.6 数据折旧

3.7 估计生产函数

四、估计结果
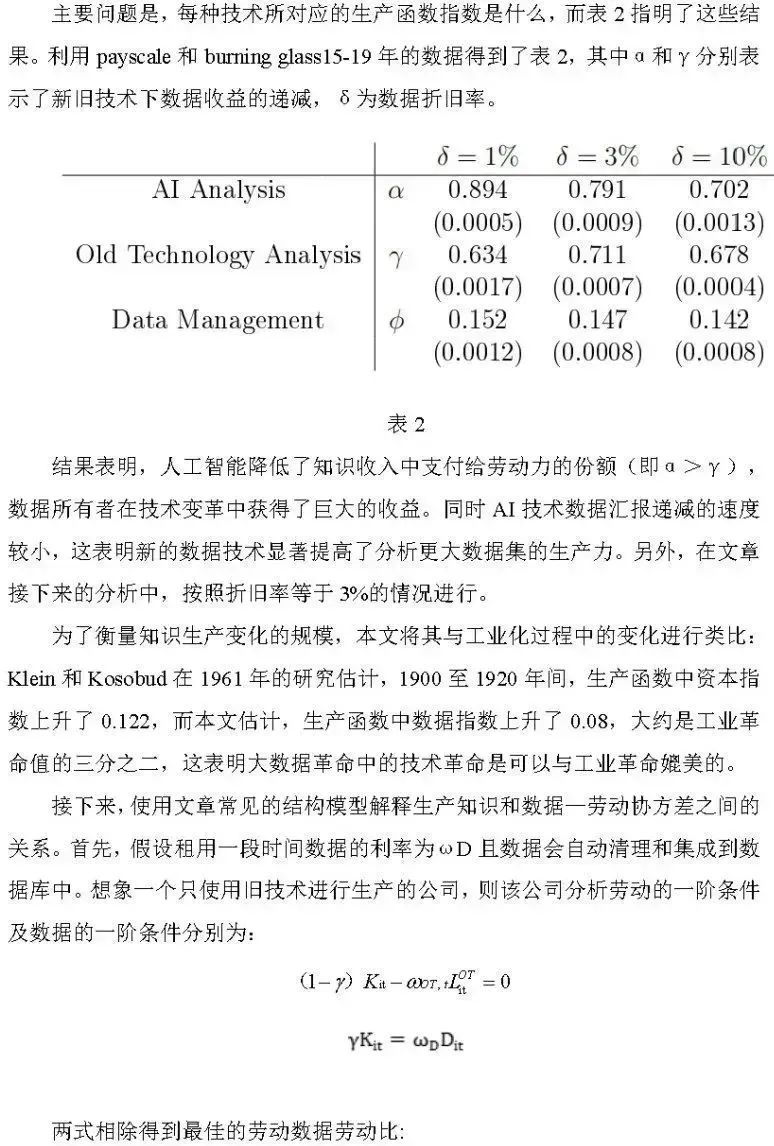
4.1 比较从工业化到知识生产的变化
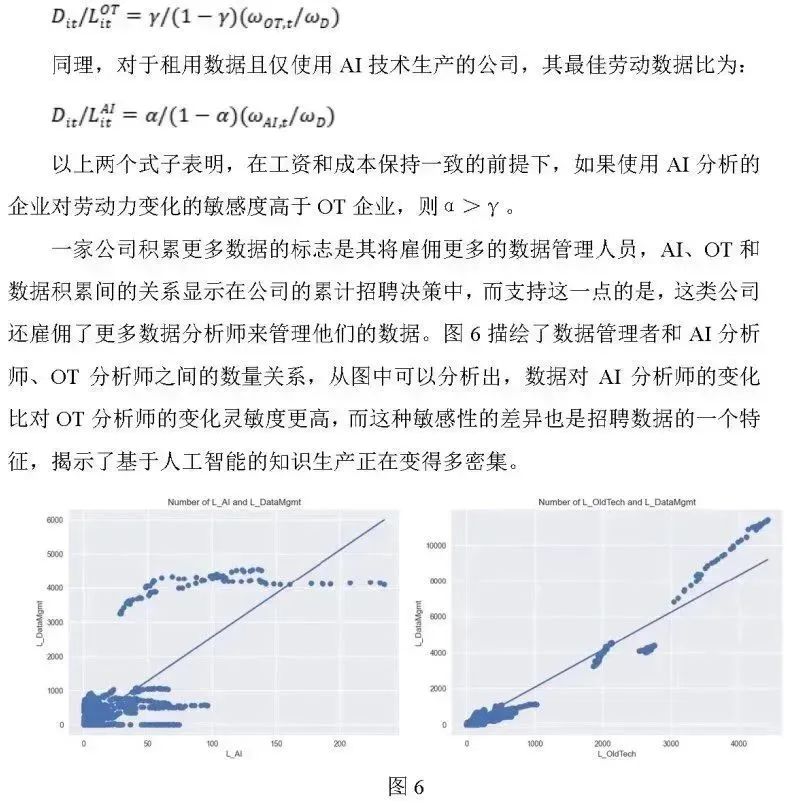
4.2 数据正在取代劳动力吗

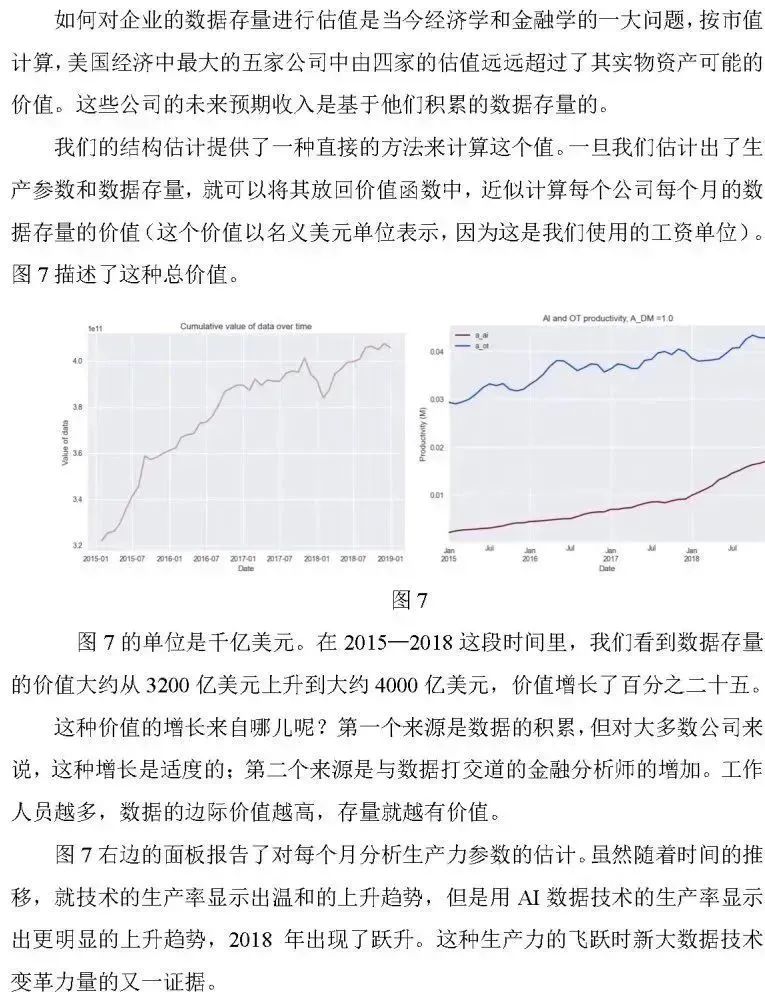
4.3 估计数据的价值
五、结论
现代话语通常将新的大数据技术描述成第二次工业革命,而我们知道,工业化的关键特征是要素份额发生了变化,因此,如果说大数据技术是知识生产的工业化,那么它们应该为数据提供更少的递减收益。本文通过对知识生产建模来探索这一假设,描述了劳动力和数据如何用柯布道格拉斯生产函数混合起来生产知识,然后用财务分析中的工资和劳动力来估计知识生产函数的指数。通过分析,我们发现拥有更多数据的公司倾向于雇佣更多的大数据或AI工人,这表明,大数据技术是一种正在改变生产要素组合的技术,它将改变未来的劳动收入占比。生产函数发生了实质性变化,这种变化与工业化带来的变化相当。因此,我们认为将这种变化描述成一种新型工业化是可行的,即大数据技术是第二次工业革命得到证实。
关于我们模型的两个拓展也许是有用的:一种是关于知识生产中规模不变的假设。生产新知识变得越来越困难,这是可能的。我们使用恒定收益一方面是为了便于与工业化进行比较,工业化常使用这样的生产函数,另一方面,非恒定收益的情况下,关于确定市场工资或要素份额的最佳方法存在争议,陷入这样的争议会分散本文的注意力;另一个延伸是考虑市场力量,生产知识的公司生产差异化产品,使其能获利,修正这一点会使模型更加复杂。
此外,我们的估计仅针对一个部门中从事一种工作的人,而在其它行业大数据也可能会改变产出,因为机器学习在其他大部分领域还未被广泛采用,要完全了解我们正在经历的数据技术变革的规模和后果,还有很多工作要做。
下期预告
时间:2023年5月26日下午18:30-21:05
地点:南开大学八里台校区经济学院圆阶305教室
论文:
Eaton, Jonathan, David Jinkins, James R. Tybout, and Daniel Xu. Two-sided
search in international markets. No. w29684. National Bureau of Economic Research, 2022.
文稿:郑烨佟 罗依璠
编辑:刘书渊 程一然
审校:何秋谷
2023年6月12日