云鹰读书会2023第27期(总第154期)
2023-06-212023年5月12日下午,南开大学经济学院云鹰读书会在圆阶305教室“数字经济与贸易科研训练:理论”课堂上顺利进行,本次读书会由2021级本科生刘嘉骥、金仕坤同学展示Maryam Farboodi和Laura Veldkamp的NBER工作论文A Growth Model of Data Economy,由国际经济贸易系何秋谷老师跟进指导,助教郑佳豪提供答疑。
特别鸣谢
本次云鹰读书会由南开大学国际经济贸易系
系友苏武康博士赞助支持
摘要
本篇文章主要构建了一个关于积累数据以促进自身发展的经济体的经典增长模型。本文中的经济体积累的数据具有以下特点:数据是经济活动的副产品;数据作为一种信息被用于消除未来的不确定性;不确定性的减少将提升企业的利润率。模型主要解释了为什么数据密集型的产品和服务能够被免费提供、众多处于起步阶段企业是负利润的以及经济体中的大型企业的利润主要来自于数据。同时模型也解释了单纯依靠数据积累而没有技术提升无法产生持续性的增长的原因。
目录
一、引言
二、基础模型
三、数据经济的特征
四、结论
一、引言
1.1 背景
当经济从农业转向工业时,经济学家聚焦于资本积累,并将土地从从生产函数中移除,随着我们从工业经济转向知识经济,投入的性质再次发生变化。在信息时代,生产愈发地以信息为主,特别是数据。尽管信息收集和使用的历史与记账簿一样悠久,但最近发生在计算机和人工智能(AI)方面的创新却使我们能够更高效的使用更多的数据,那么这种数据经济又将如何发展呢?因为数据是非竞争性的、用于提高生产率并且可以自由复制(具有规模报酬),故此当前一般将数据增长和创意或者技术进步等同起来。针对这一观点,文章构建了一个简单框架阐明了数据的积累在短期内会有递增和递减的回报,但在长期内,数据的积累与资本的积累相同,仅靠自身是无法实现持续性增长的。数据是可以被编码为0和1的而二进制序列。其宽泛的定义包括文学、视觉艺术和技术突破。
在本文中,我们将关注点局限在大数据上,因为大数据是是技术产生地方,这些突破催生了关于新信息时代和新经济的讨论。机器学习和人工智能是一种预测算法,可以用于预测商品的需求、图片的内容和广告对销售收入的影响。许多大数据企业通过数据的交易进行这些预测。这些数据包括在线卖家的个人信息、商店附近的交通模式的卫星图、用户评论的文本分析和经济经济活动的记录等,这些数据可以被用于预测公司及其产品线的销售额、收益和末来值,也可以用于打广告或者窃取其他公司的业务。
1.2概况
数据经济是否存在新的经济学理论?在信息时代,生产越来越依赖于信息,尤其是数据。很多公司,特别是价值最高的美国公司,因为它们积累的数据而备受关注。自从Wilson(1975)以来,我们就知道想法、信息、数据和其他非竞争性投入具有规模收益。由于大公司从数据中获益更多,它们产生更多数据并变得更大,因此数据通常具有递增的回报。
然而,任何数据科学家都会告诉你,数据的回报是递减的:大部分预测值来自于最初的几次观察。要理解这些相反的力量及其对经济的意义,我们需要构建一个新的动态均衡框架,并将数据视为状态变量。我们的数据经济模型告诉我们,长期动态和福利类似于资本积累和回报递减的经济。然而,短期具有新的动态特征,例如收益递增、负利润和商品数据易货。
这篇论文的主要贡献不在于特定预测的探索,而在于模型作为工具的应用。鉴于模型假设,一些预测并不令人意外。但是,这些预测的现实主义支持了该框架作为相关且有用的概念。
更重要的贡献是提供一种评估数据、衡量其影响并清晰思考数据积累总体经济后果的工具。数据的衡量和评估是复杂的,因为客户经常提供他们的数据以换取免费的数字服务。我们的价值函数将商品和数据赋予正值,即使它们的交易价格为零。通过这样做,它使聚合模型超越了价格加权估值,并以一种更新的方式思考数据经济中的经济价值。
对数据经济进行建模是一项具有挑战性的任务。一个关键特征是公司/客户行为会产生数据,这是一种信息形式。考虑到这些行为所产生的信息,在选择行动时进行积极实验是重要的。微观级别的积极实验模型通常很难解决,即使没有复杂的平衡力。此外,一个有用的数据经济模型应将数据视为长期存在、会贬值和可交易的资产。这需要使用递归Bellman方法来处理数据状态变量。
对于估值和折旧,对于a)从积极实验中获得的数据,b)在多个时期产生价值,c)在市场上以均衡价格交易,并且d)最终贬值的数据,需要一套新的工具进行简单估值。虽然生成的模型看起来像一个标准的DSGE框架,但实现这种程度的简化需要谨慎处理。
第1节的模型描述了一种特定类型的数字化信息,即通过交易产生的数据,公司利用这些数据通过准确预测未来结果来优化其业务流程。随着机器学习和人工智能的进步,数据经济正在蓬勃发展。预测算法起到了关键作用。它们需要大量通过交易自然产生的数据,如买家特征、交通图像、用户评论的文本分析、点击数据和其他经济活动证据。这些数据通常用于帮助公司通过预测需求、成本、收入、劳动力需求、定向广告或选择投资或产品线来进行优化。
由于其简洁结构,该模型可以在许多方面得到应用和扩展。我们在论文中探索了一些应用,而结论中还讨论了其他问题,如不完全竞争或公司规模分散。虽然向主模型添加功能可以使其更好地解决特定问题,但保持模型的简洁性使其具备灵活性。
第2节说明了如何对数据进行估值和折旧。这两个概念都很难直接观察到。然而,我们的模型提供了一种估计特定类型数据价值衰减速度的方法。贝叶斯定理及其相关的卡尔曼滤波器决定了信息准确性下降的速度,并为我们提供了一个简单的估计过程。了解数据如何贬值使我们能够建立一个递归价值函数结构,类似于评估资本的结构,但反映了作为积极实验的生产价值和数据贬值的独特方式。
第3节探讨了公司在达到稳定状态(短期)时所采取的路径。当数据稀缺时,由于数据反馈循环,其回报可能会增加。更多的数据提高了公司的生产力,从而导致更多的生产和交易,进而产生更多的数据,进一步提高生产力和数据生成。这是数据稀缺时的主要驱动力。收益递增也可能导致贫困陷阱。数据水平低的公司利润较低,使得几乎不生产成为最佳选择。但是,少量生产的数据很少,导致公司缺乏数据。公司甚至可能选择以负利润生产,作为一种昂贵的数据投资形式,尽管账面价值很小,但股票市场估值可能仍然很高。这解释了观察到的数据易货现象。许多数字服务(如开发成本高昂的应用程序)以零价格提供给客户,以交换客户的数据。以零货币价格进行的服务交换客户数据是一种易货交易。
第4节考察了长期的数据经济。我们从一个思想实验开始:在没有任何技术进步的情况下,数据能否维持增长?这类似于Solow(1956)提出的关于资本的问题。我们发现,从长远来看,收益递减是主导力量。长期数据经济看起来类似于长期资本经济,但原因不同:首先,预测误差只能降为零,这为数据增长设定了一个自然限制。其次,不可预测的随机性限制了公司预测的准确性。这些力量中的任何一个都会确保当数据充足时,其回报递减并且无法维持增长。当然,如果我们改变模型,将数据视为研发(R&D)的输入,那么数据可以维持增长(第4.3节)。信息并不意味着一切皆有可能。关键是为了评估提供信息的事物:我们应该像宏观经济学家通常区分常规资本投资和研发投资一样单独衡量用于研发的数据。
当前一些最激烈的政策辩论围绕着公司对数据的使用展开。考虑到监管和福利方面的需求曲线,我们对家庭层面的微观模型进行了建立。
第5节探讨了这一点,并发现尽管存在非竞争、收益递增和数据作为副产品的生产,但均衡选择是有效的。这并不意味着数据不会造成伤害。这只是意味着我们的模型所描述的简单力量本身不会损害福利。我们扩展了模型以捕捉数据的外部性,例如隐私丧失或通过数据定向营销从竞争对手那里窃取业务。这些负面外部性显然会刺激过度的数据生产,进而扩大商品生产,以产生额外的数据。数据经济是一个复杂的领域,需要更深入的研究和经济学家、政策制定者和从业者之间的广泛讨论。
1.3文献综述
在增长文献中,我们的模型建立在Jones和Tonetti(2018)的基础上。他们探索了不同的数据所有权模型如何影响经济的增长率。我们模型与其他模型的关键区别在于数据是用来预测随机变量的信息。在Jones和Tonetti(2018),Cong(2020)的相关研究下,数据直接作用于生产效率,它并不是信息。信息的基本特征是它减少了不确定性。当我们将数据建模为信息而不是技术时,Jones和Tonetti(2018)关于数据作为一种隐私具有效益的结论可能仍然成立。但在这个模型中经济并不是长期增长而是长期停滞。在“干中学”模型中(Jovanovic和Nyarko,1996;Oberfifield和Venkateswaran,2018)和组织资本(Atkeson和Kehoe,2005),企业也积累了一种形式的知识,但对于经济来说结论会有所不同。与用来预测的数据不同的是,知识积累不是长期收益递减的,并且它不是一种可交易性资产。数据短期收益递增不同于具有收益递增性质的增长模型Farmer和Benhabib(1994),因为它们是基于企业间的正外溢性,而我们的是企业内部的反馈环。商业周期中的信息摩擦的研究(Caplin和Leahy,1994;Veldkamp,2005;Lorenzoni,2009;Ordonez,2013;IlutandSchneider,2014 ;Fajgelbaum et al.,2017) 。数据反馈环的早期版本:更多的数据可以带来更多的生产,更多的生产产生更多的数据。在这些模型中,信息都是经济活动的副产品;企业利用这些信息来减少不确定性,制定决策。但关键不同点在于,信息是一种公共产品,而不是私人资产。本文中的私有资产假设改变了企业生产数据的动机。在这些早期的模型中,金融公司利用数据来预测商业周期,而不是最优的企业策略。我们将数据作为特定行业或公司中所属于企业的私有财产引入到模型中。探索数据与创新之间的相互作完善我们的模型。例如,Agrawal et al(2018)开发了一个基于组合的知识生产函数,并将其嵌入到Jones(1995)的经典增长模型,探索人工智能的突破如何提高发现率和促进经济增长。我们的工作分析了在缺乏技术变革时的大数据和新的预测算法。一旦我们了解了这个要点,我们具有对数据和创新顶部的洞察力。在金融学文献中,Begenau et al.(2018)探索了增长是如何在财务数据的处理中影响企业规模。他们没有对企业使用自己的数据进行建模。还有一篇文献是关于数据驱动决策,探究数据在微观经济层面的重要性。我们添加这些活动的综合效应。最后,五方程的简化模型Farboodietal(2019)知识存量可以作为一个状态变量。这是一个局部均衡的数字训练,旨在探索具有异构数据企业的规模。本文构建了一个我们用分析方法求解的总量均衡模型,具有更丰富的特征,探索了不同的问题。数据市场、非竞争数据和调整成本的新特征是一个大的突破。这些新的边际分析回答了总体动态和长期产出主要问题的答案。
1.4 贡献
文章的主要贡献在于为更加理性的思考数据积累及其经济影响提供了一个工具,同时也回答了在思考数据经济时,应当如何从现有的集合框架如索洛(1956)模型和以其为基础的现代DSGE模型中调整思维方式。此外,文章模型也为测度数据提供了指导,能够从中理解数据的定价行为和交易价格为零时企业的经济行为。文章的结论说明了数据就如同资本投资,如果非数据技术(生产力)持续改进,数据将有助于寻找新技术的最优利用方式,数据的积累也可以通过减少技术创新的不确定性来降低技术创新的成本,或者通过提高回报以增加创新的激励。
二、基础模型
2.1 模型的假定







三、数据经济的特征
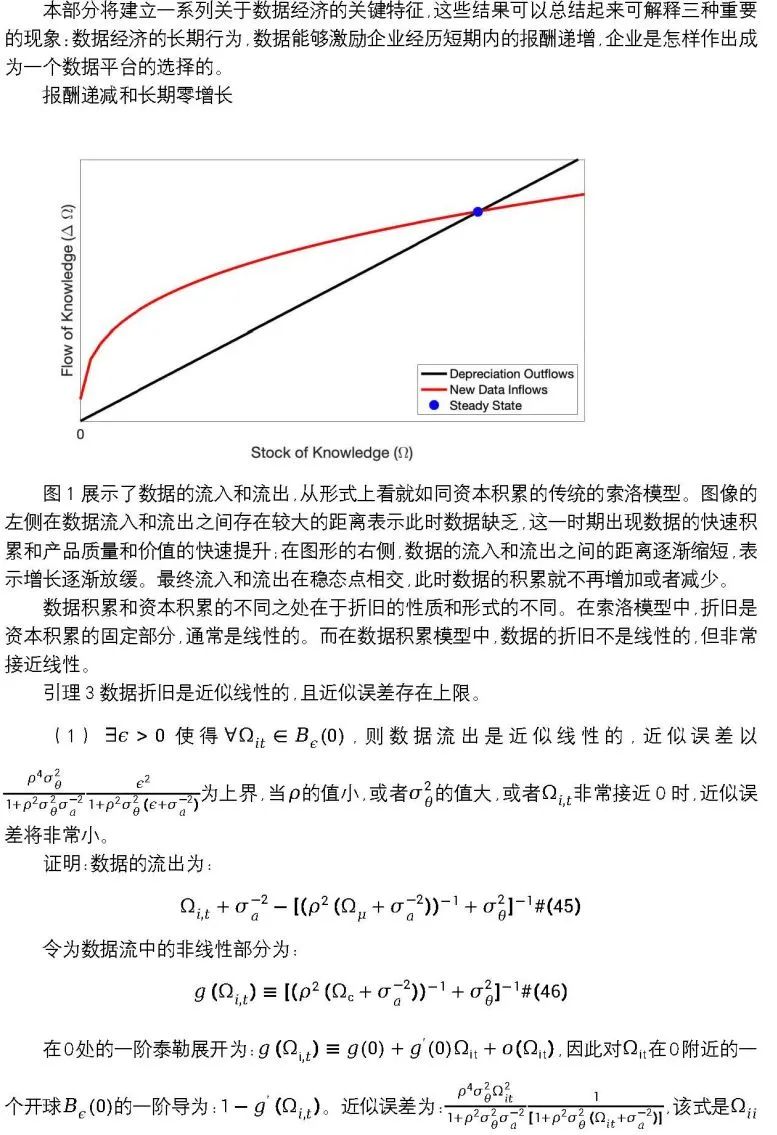



2.2 报酬递增、数据陷阱和进入壁垒


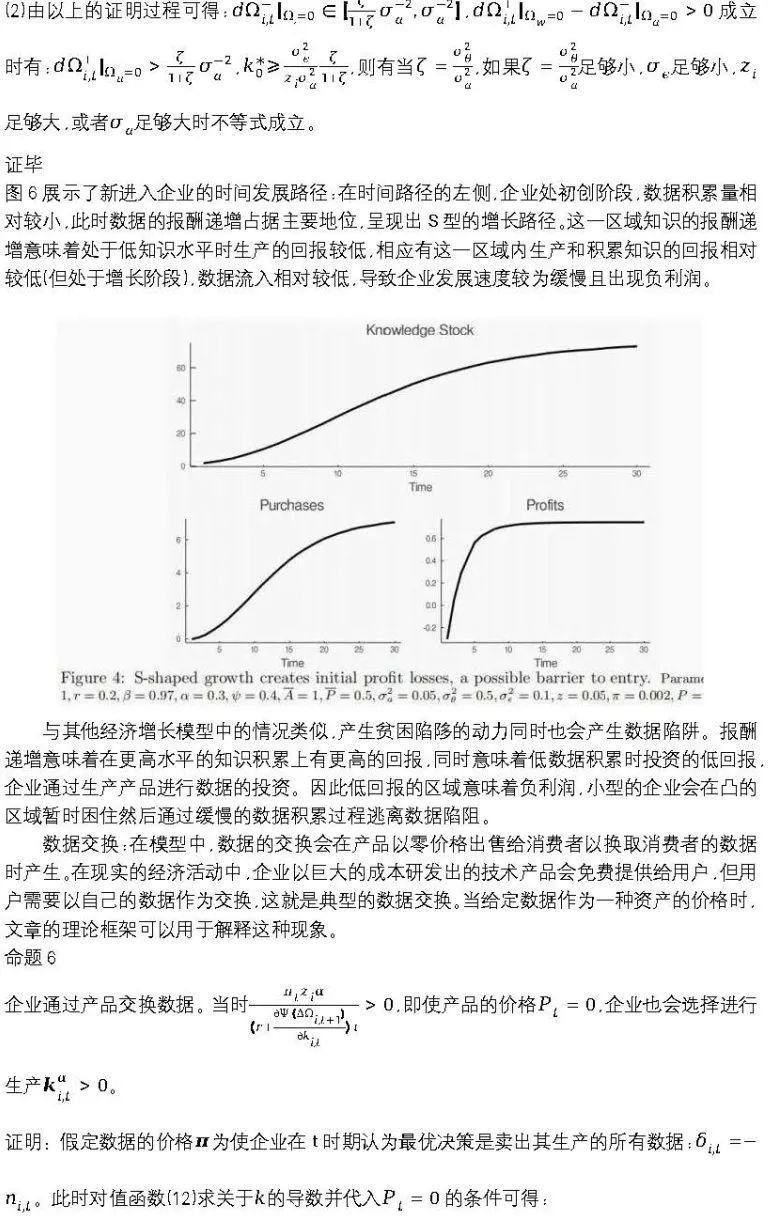



四、结论
数据交易的经济分析与技术和资本的分析相似,但是与两者都不同。当经济体经济积累数据时,经济体总体的增长与仅积累资本的经济体相似,即收益递减且是有界的。但是数据经济中的达到稳态的过渡路径是不同的,一些区域或时段中,数据的生产过程以及相应的反馈循环,使数据的报酬递增成为可能,但数据报酬递增会造成数据的贫困陷阱。当存在数据的交易市场时,这种数据陷阱的影响会得到缓解,但是生产的回报处于低水平。尽管数据的积累和分析可能是“新经济”的标志,但是这种新经济中有许多古老而熟悉的经济力量在发挥作用。
下期预告
时间:2023年5月19日下午18:30-21:05
地点:南开大学八里台校区经济学院圆阶305教室
论文:The Changing Economics of Knowledge Production
文稿:刘嘉骥 金仕坤
编辑:刘书渊 程一然
审校:何秋谷
2023年6月21日