王永进:数字时代的经济学研究(漫画版)
2023-12-28摘要:经济学研究本质上是一个从纷繁复杂的经济现象中去破解蕴含在其中的“信息代码”,并运用这些“信息”造福人类的过程。从“信息观”的角度来看,经济学研究可以划分为提炼假说、理论建模和经验分析这三个阶段,而经验分析又包括简约估计、结构估计和机器学习三种方法。本文旨在从信息观的角度对经济学各类研究方法的适用场景以及在应用过程中容易出现的“滥用”、“误用”的问题进行梳理,帮助初学者一方面可以规避经济学研究中的常见陷阱,另一方面则能够根据研究问题和局限条件的差异来选择适合的研究方法。本文在对已有研究方法进行评述的过程中,也尝试对数字经济时代经济学研究所面临的机遇和挑战进行展望。
关键词:经济学研究方法;理论建模;简约式估计;结构式估计;数字经济
* 王永进:南开大学经济学院国际经济贸易系,博士生导师;电子邮箱:wyjin17@163.com;地址:天津市南开区卫津路94号;邮编:300071。本文是发表在《新经济》2023年第12期(总第572期)的同名文章的拓展版。本文观点仅代表本人个人观点,与所在单位无关。特别感谢中国人民大学刘瑞明教授和浙江大学张川川教授阅读全文,并提出很多建设性的建议。文责自负。
“直到今天,我还是没有失去勇气。我会尽到作为经济学家的职责。为了传达心中的真理,我永远不会感到疲劳。”
——路德维希·冯·米塞斯
轻轻地,数字经济时代来了,它的脚步越来越近了。或许五年或十年之前,还有人在怀疑数字技术革命是否会到来,或者认为它的到来是很遥远的事。然而,今天,多数人已经意识到数字经济时代已然来临。它来得很快,来得很突然,来得让人有点不知所措。一时间,区块链、大数据、机器学习、人工智能、物联网等新的科技词汇蜂拥而至,让人既感到欣喜、激动又有些恐惧战惊。与传统的工业经济和农业经济相比,数字经济不仅产生了新的生产要素,获得了新的生产动力,而且还在替代越来越多的工作岗位。于是,站在时代的风口浪尖上,我们不得不解答下面的数学题:“人-AI=?”这是时代给我们出的题目,谁都不能回避。
毋庸置疑,要成功解答这个问题涉及到科技、经济、政治、社会、伦理和宗教等方方面面的知识和智慧。这显然不是某个个人所能解决或面对的。为此,本文并不是想给一个终极的答案,而是从“信息观”的视角对经济学研究的各种方法进行梳理和总结,并试探性地展望把数字经济时代可能面临的机遇和挑战。[1] 毕竟,“信息”乃是数字经济的内核。
本文结构安排:第一节从信息观的视角对经济学研究进行梳理和鸟瞰,并把经济研究分为提炼假说、理论建模和经验研究三个环节;第二、三、四节分别对经济学研究的这三个阶段进行详细展开,梳理了每一个阶段常遇到的问题,并讨论数字经济对这三个部分的影响。其中,第四节对简约式估计和结构式估计进行了系统的比较。第五部分进行总结。
[1]我明知道写这样的题目是容易引起争议的。因为,文字的表述常常容易引起误解。很多时候我以为我写下的是我自己所想的,然而读者或许依然还会错意。然而,学科的进步正是在不断的争议中进行的。为此,我还是勇敢地提起了笔。这倒不是说自己的学问如何了得,而是源自一种长期的感动和执着。其一,我自己的知识结构比较庞杂(故而每个领域都不精纯),早先曾经涉猎制度经济学、区域经济学、国际经济学和产业经济学等多个领域;其二,在研究方法上,本人对于理论建模、简约式估计和结构式估计等方法也均有所了解,并在国内外期刊发表过一些论文;其三,自己从2018年就开始阅读数字经济领域的相关文献,并形成了一本40万字的《数字经济学》教材。因此,对于数字经济的相关问题一直在持续关注和思考;其四,我一直对经济学的方法论感兴趣,在南开大学举办读书会的过程中,也比较侧重引导同学们从科学观的角度来引导学生读文献和做研究;其五,当年我学经济学的过程主要是靠自学,因此,走过不少弯路。每每想起来都觉得有些遗憾。为此,但凡有点心得,就希望能够把自己做研究的经验分享给同学们,以使大家少走弯路。这或许是我明知不可为而为之这种执念的动力来源吧。
第一节 经济学研究的“信息观”
人类经济社会的运行规律,其本质是一个“信息集合”。经济学研究就是不断破译蕴含在经济现象底层的“信息代码”的过程。不管是人还是人工智能,都不能保证在特定时空范围内所萃取的信息是无偏的。我们可以不断地去挖掘这个“信息集合”中的元素,却不知道这个“信息集合”的边界在哪里。为了保证信息提取过程的“无偏性”和“有效性”,我们既需要运用我们的“理性”思考能力,也需要“实证精神”。
经济学是一门“实证科学”。其中,“实证”一词的英文是“positive”,而不是“经验分析(empirical)”。“实证分析”通常是与“规范分析”相对应的。所谓的“规范分析”,指的是从“社会规范”的角度来看某件事好不好,是主观的价值判断。实证分析方法既包括经验分析(即中文语境下的实证检验),也包括理论分析。马克思发表在1945年左右出版的《德意志意识形态》明确提出了“实证思想”。他指出,“在思辨终止的地方,在现实生活面前,正是描述人们实践活动和实际发展过程的真正的‘实证科学’开始的地方”。
因此,实证科学的起点乃是现实。而一个完整的经济学研究过程实际上是一个长长的链条,其起点是现实,终点是真理(或许根本没有所谓的绝对真理),中间则是“提出/修订假说”和“经验检验”这两个阶段不断的循环往复(图1)。而提出理论的过程则可以拆分为提炼假说和构建数理模型这两个步骤。综上所述,我们把经济学研究的过程划分为三个阶段:提炼假说、构建理论模型和经验研究。
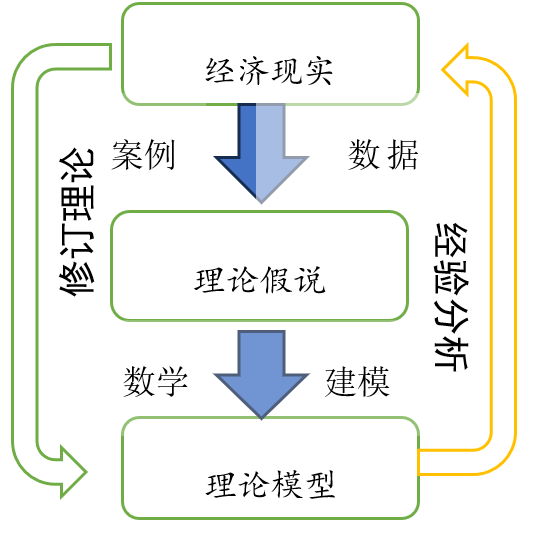
图1 经济学研究过程
或许有人认为很多理论假说是通过数理演绎推导出来的。但是,多数的经济学大师,如Arrow、Krugman、科斯等,他们在得出理论假说的过程并不需要通过数理建模,而是依靠经济学逻辑或是所谓的直觉。在理论模型写出之前,他们的心中已然有一条完整的逻辑传导的路线图。只是为了让普通人能够准确理解其思考过程,他们不得不借用数学语言让大家去明白自己的思维过程。其实,自然科学领域又何尝不是如此呢?!是的,学问到了至高境界,就不必受到表现工具(语言文字、数学)的限制了。而学科的传播和进步却不能只停留在头脑理论,而是要写下来。至于是用语言文字表述还是用数学演绎,只是方式方法问题。
第二节 从经济现象到理论假说
在大数据出现之前,人类提炼经济规律的方式是通过人脑对零散的案例进行概括和总结,并形成理论假说。亚当斯密从现实观察中发现:“我们得到的一切并不是靠着屠夫、酿酒师和面包师的恩惠,而是因为他们对自身利益的看重。”似乎有一只无形的手在引导人们的交换。虽然这些从零散的案例中所提炼出来的“信息”并不是基于全部的样本,但是依然可能是普遍性的规律。实际上,战国时期的韩非子早在两千多年前就提出了类似的观点:“医善吮人之伤,含人之血,非骨肉之亲也,利所加也。故与人成舆,则欲人之富贵;匠人成棺,则欲人之夭死也。非舆人仁而匠人贼也,人不贵,则舆不售;人不死,则棺不买。情非憎人也,利在人之死也。”由此可知,有些经济规律虽然是在特定的地域和历史发展阶段所提出的,但依然是有普遍意义的。
当然,这并不能保证所有以这种方式提炼出来的理论假说都是永远适用的。一方面,经济运行规律本身是随着经济发展阶段而不断发展变化的;另一方面,人类个体的认知能力也受到时间和空间的制约。这是为什么经济学理论要不断接受现实检验的根本原因。例如,马尔萨斯所提出的“人口论”在农业社会是适用的,在工业社会则未必适用,但从更长的历史区间来看,则又可能是对的。
需要特别指出的是,由于现代经济理论通常是以数学模型的方式呈现出来的,因而很多人可能会误以为理论假说是通过数学推导得出的,于是很容易犯“以数学模型推导代替经济学思考”的错误。这样的错误在AI的时代可能是灾难性的。因为,能否深入的思考正是人和AI的一个重要区别。在AI时代,人类要生存需要的不是和AI赛跑,而是与AI合作,让那个AI为人类所用。
数字经济时代给人们带来的一个错觉是:当大数据成为关键生产要素时,未来的研究应该会大量用到人工智能。该观点忽略了人工智能方法要发挥作用是有条件的,而且人工智能本身也具有局限性。
其一,只有数字化的信息才能采用人工智能进行数据分析。然而,并不是所有的信息都可以数字化。很多重要的信息通常是以零散的、不可编码的方式存在于世界中的。例如,很多原创性的思想实际上是来自于生活中的个案。
其二,数据采集以及数据怎么用依然需要人的经验或监督。也就是说,虽然人工智能可以帮助人类采集数据,但人需要首先决定需要采集哪些数据,接下来才是人工智能的工作。例如,工业场景中的设备故障检测,当要判断轴承外圈是否发生故障时,需要将注意力放在提取轴承外圈故障特征频率的能量上,而其他的频谱成分就并不那么重要。而当要分析内圈故障时,看的又是另外的频率特征了。
其三,人工智能并不能代替人类所有的脑力活动。至少从现阶段来看,人工智能虽然在数据计算和排列组合上的能力要胜过人类,但是对于一些创造性和抽象性活动,人工智能还是无法完成。实际上,很多原创性活动并不是按照常规逻辑来推理出来的,而是依靠突如其来的联想,也就是所谓的“灵感”。此外,对问题识别是对分析对象的抽象过程,即提最关键有效的少量信息来代表全局,而不是盲目地基于大数据来进行海量计算。
图2 机器学习会变成“屠龙术”吗?[1]
其四,在大数据时代,多数人要面对的可能不是数据的海洋,反而是“数据荒漠”。这一点是由数据的属性决定的。数据的规模经济特征意味着数据要聚集在一起才能发挥作用;而算力则需要大量的沉没成本投资,小企业是很难承担的。这两个技术特征意味着数据最终会被少数企业或者政府所垄断。而数据的所有者是不愿意与太多人分享数据的。如老子所言,“国之利器不可以示人”。因此,数据一旦成为国之利器,从而涉及到商业机密和国家安全,就很难被个人所接触到了。从某种意义上来说,个人手中掌握这么重要的资源可能也并非幸事。正所谓,“小儿无罪,怀璧其罪”。强大的资源往往是以强大的实力为后盾的,否则资源的“租金”就会被无休止的寻租活动所耗尽。这也是富可敌国的“中本聪”(比特币的创造者)把自己的真名隐藏起来的原因。
[1]此图由王籽奇同学采用CHATGPT绘制。
第三节 理论假说到理论模型
马克思曾经指出,“一种科学只有在成功地运用数学时,才有可能趋于完善。”[1] 这是因为文字表达的思想常常是晦涩难懂的,因此,既不利于人们之间的“信息”交流,也不利于开展“经验研究”。毕竟,我们首先要清楚地表达所提取的“信息”的内容是什么,然而才能用现实进行检验。含混不清的理论是没有任何价值的。
1. 什么是好的理论模型?
一个好的理论模型通常需要达到下列标准:
第一, 能够解释经济现象。理论模型本是为了解释经济现象,不能解释现象的理论模型无论多么好看,终必归于无用,既不会被人记住,也不会被发表。
第二, 简化到存在显式解、并能用故事的方式讲出来。理论模型的作用在于引导人们从纷繁复杂的现实世界中抽离出来,去把关键的逻辑线索展现出来,帮助人们去理解真实的世界。Varian曾经把理论模型比喻为“地图”,如果地图和现实完全相同,那么,地图还有何用处呢?所以,好的理论模型常常在一些无关紧要的枝节上做出偏离现实的、甚至是匪夷所思的假设。从这个角度来看,理论与现实存在距离是必然的。
第三, 理论模型的结论不是显而易见的,而是既在意料之外、又在情理之中。这就要求不能用现实来解释现实,假设与结论之间有一定的距离。因为显而易见的结论本不需要理论建模来阐述。之所以需要理论模型,是因为现象和经济解释较为复杂,用语言文字可能不容易表述清楚。因此,不能为了凑篇幅或者为了看起来好看而写理论模型。
第四, 假设和传导机制符合现实,或者有文献支撑。虽然经济学模型的终极目标是要解释现实,但并不能以此为理由来做出错误的假设。这就好比一个人坏人,本来是要做坏事,但没想到却阴差阳错地成就了一桩美事。难道,我们就可以因此说,这个坏人的出发点是值得表彰的吗?!断乎不可!
第五, 不能用数理推导代替经济学逻辑,即能够用语言文字清晰地解释假设以及从假设到结论的经济学传导机制。毕竟,经济学不等同于数学。经济学之所以与数学有区别,就是在于把经济学涵义赋予数学符号。这一点无论对于写论文还是读论文都至关重要。很多人会在推导完数学模型之后就误以为自己已经掌握了文章的关键,岂不知这只是理解经济模型的第一步而已。
[1]有人把这句话的后半句翻译成“是一门科学走向成熟的标志”。其实,马克思的原意并不是说,使用数学后一门科学就成熟了,而是只有使用数学了,一门学科才有可能走向成熟和完善。这两种翻译的区别在于:一种是把数学作为学科成熟的标志;而另一种则是把数学应用作为学科走向完善的前提条件。
2. 如何训练理论建模能力?
对于如何建立理论模型,哈尔·罗纳德·范里安(Hal R. Varian)曾经专门就此写了一篇题为“如何利用你的业余时间来写经济模型”(how to build an economic model in your spare time)的文章。2008年的诺贝尔经济学奖得主保罗·克鲁格曼(Paul Krugman)在一篇题为“我如何工作”(How I work)的文章中,也详细地介绍了他写经济学模型的经验。然而,遗憾的是,他们写的这些经验虽然很让人感到羡慕和惊讶,但读者们在读完之后,可能还是依然茫然无措。原因是,他们写的这些方法只是适合于那些天才或者已经会经济建模的人。对于毫无建模经验的人而言,他们提出的方法并没有什么实际的指导价值。其实,这也难怪。这些从经济学金字塔顶端走出来的学者似乎对于那些经济学大师们口口相传的理论建模法则烂熟于心了,以至于很难理解处于金字塔底端的普罗大众所面临的实际困难。对于中国的同学们而言,真正有价值的建议必须从零基础开始。


图3 哈尔·罗纳德·范里安(左)和保罗·克鲁格曼(右)
笔者从硕士开始就一直对经济理论建模感兴趣。由于国内经济学理论教育与国外的经济学教育实在是有很大的差距,因此,也是兜兜转转走了不少弯路。我是直到2008年暑假参加中国人民大学组织的“企业理论前沿与中国制度变迁”暑期学校的时候才窥见经济建模的门径。在这个暑期学校中,从研究机制的Kim Sau Chung,讲授谈判理论的Stephen Chiu,一直到主攻声誉理论的Steven Tadelis,不管是在数学上多复杂的理论,他们总是能够通过案例将其“化繁为简”。在瞻仰他们强大的数学建模能力的同时,我也对他们对复杂模型的简化能力感到震撼。是的,经济学理论是不仅可以讲给外行听的,而且还可以讲给妈妈听,甚至是可以讲给孩子听。
当然,我是直到女儿上小学一年级的时候才发现:经济学理论是可以讲给孩子听的。在每一天陪伴孩子的过程中,从简单的需求定律到外部性、逆向选择、道德风险和比较优势理论,我发现这些高深的经济学其实就存在于孩子的日常生活之中。经济学不仅能够我们带来精神上的愉悦,而且能让我们生活地更有智慧。
由于我的专业是国际贸易和世界经济,所以我当时学习的目标并不是要在机制设计领域有所建树,而是去学习他们的思考方法和建模技巧。因为我知道,这些技能才是真正对我有用的。于是,带着这样的心态,我度过了一个充实忙碌的暑假。在学习结束的时候,我终于发现了理论建模的奥秘。2009年我继续参加了上海财经大学举办的“国际贸易与投资”暑期培训班。在一篇篇论文的讲解过程中,我一次次地印证了2008年自己总结的经济理论建模训练方法的有效性。
那么,究竟怎么才能有效训练自己的理论建模能力呢?在我看来,除非你是一个天才,那么训练经济学理论建模能力首先要从读理论模型开始。大家或许会疑问,读模型有什么难的,我们“三高”还有数理经济学的课程上不是都训练过吗?如果你把读理论模型理解为数学推导,那可就错了。如果只是推导数学模型,那么,用这样的方式来读论文对你的经济学思维训练不仅无益,反而有害。一个完整的论文阅读过程需要经历“得其数”、“得其志”和“得其人”三个阶段。对此,我曾经在《经济学家茶座》写过一篇题为“从‘孔子学琴’谈理论文献的阅读方法”的文章[1],后来又在《数字经济学》这本书的引言中再次阐释了理论文献的阅读方法。因此,在这里我就不再赘述了。
当然,要想拥有良好的经济学建模能力,除了“读”,还要学会简化模型和改写模型。不能简化模型,就说明对文章的理解还不到家。特别是对于近期的经济学论文更是如此。现在经济学理论比较流行复杂的模型。很多论文的数学推导动辄四五十页,这对于读者来说很不友好,而且也不利于思想传播。请注意,我不是在宣扬“模型无用论”,也不是说这些文章把模型写的这么复杂是毫无用处的,而是说,先从一个简单的模型来开始讲不仅更易于读者理解,而且还对于训练自己的经济学理论思维能力也大有益处。
在写《数字经济学》第13章“大数据的经济分析”时,我们想为读者介绍Jones和Tonetti于2020年发表在《美国经济评论》上的这篇论文[2]。可是,这篇论文的原文的数学附录足足有70页之多。难道我要把这70页内容都放在书中吗?当然不行。于是,笔者就运用起了失传已久的“面目全非脚”和“还我漂漂拳”,对模型进行了重新改写。最后,总算成功地把论文缩短为10页。再举一个例子,在撰写第2章“消费者搜寻理论”时,我们想展示MacMinn(1980)这篇论文。但在读原文但过程中我发现,作者在证明过程中直接引用了拍卖理论的一个结论。[3] 难道为了理解消费者理论,我们还得先学完拍卖理论吗?显然,这对读者是非常不负责任的。类似的例子还有很多,我就不再一一列举了。这里想要表达的一个重点是,要多做简化模型的工作,简化到可以用故事把模型的核心结论讲述出来。这样做的好处是,当我们真的在现实中遇到一些经济问题是,就能够相对容易地把理论模型写出来。当然,写《数字经济学》这本书的似乎更多的是在展示模型的简化能力。为此,我打算在下一本书中,更细致的展示如何对复杂的模型进行拓展,以及从简单的故事开始写模型,怎么把简单的模型变得越来越好看。如果说,《数字经济学》这本书是在“秀肌肉”的话,那么,在下一本书,[4] 我决定充当“健身教练”的角色。
在这里,必须强调的一点是:数学好并不是写好经济学理论模型的充分条件。写好数学模型的关键并不是数学要有多好(当然不能太差),而是建立经济现象与数学之间的联系。这是写经济理论模型最难的地方,也是人工智能无法做到的。
在数字经济时代,或许数据可能变得越来越难以获得,但我们绝不应该因此而沮丧。要知道,上帝在关上门的同时,也为我们开启了一扇窗户。因为,经济社会的剧烈转型为我们提供了很多新的经济现象和研究素材。对于这些新现象和新问题,我们显然不能等到数据都成熟了才进行研究。或许我们永远都等不到数据。然而,只要我们拥有了理论分析的利器,也依然可以在纷繁复杂的乱象中拨云见日。为此,我们期待:一个理论的时代即将到来。
从经济学发展历史来看,那些重大的经济学理论不都是在没有数据的情况下发现的吗?所以,真正的困难不是没有数据,而且缺乏对现实问题的洞察力。换个角度来看,数据和信息爆炸很多时候未必能够带来更多有价值的洞见,而是使人们深陷在噪音的迷雾之中而茫然失措。
[1] 微信链接为:
https://mp.weixin.qq.com/s/4LxZHQdF1ogVO3vKt4P60Q。
[2] Jones, Charles I., and Christopher Tonetti, “Nonrivalry and the Economics of Data,” American Economic Review, vol. 110, no. 9 (Sep 2020), pp. 2819-58.
[3] MacMinn, Richard D. “Search and Market Equilibrium.” Journal of Political Economy 88, no. 2 (1980): 308–27.
[4] 书名可能是《开放型数字经济学》、《数字开放经济学》或《数字时代的开放经济学》。
第四节 经验研究方法三大武器:
简约估计、结构式估计与机器学习
1. 概述
“经验研究”在中文中通常被称作“实证研究”。此“实证”对应的英文单词为“empirical”。常用的经济学经验研究方法有三类:一是“简约式估计”(reduced form estimation);二是“结构式估计”(structural estimation);三是“机器学习”方法。需要指出的是,不管是什么经验研究方法,都是以精确可靠的数据为前提基础的。没有高质量的数据,经验分析就无从谈起。当有了数据之后,我们接下来需要做的事情就是把变量之间的关系识别出来,并进行定量评估。
“简约式估计”的重点是“因果推断”。而“结构式估计”过程则较为复杂,通常包含理论建模、实证估计和反事实分析这三大步骤。其特点是从设定假设开始,经过一系列的数学推导,得出可以被数据检验的估计等式或不等式;然后,基于模型去估计参数和进行反事实分析。虽然,结构式估计的门槛比较高,但是,这并不是意味着做简约估计更容易。无论是简约式估计还是结构式估计,都要经过提出假说、验证假说的过程。由于二者侧重点不同,因此采用了不同的工具和方法。但无论是哪种方法,要把故事讲得天衣无缝、令人信服都是高超的艺术。
与简约式估计和结构式估计不同,“机器学习”方法所擅长的并不是揭示不是变量之间因果关系,也不是变量之间的传导机制,而是运用计算机的计算能力把变量之间的“相关关系”提炼出来,并对变量的关系进行模拟和预测。如果我们把简约式估计和结构式估计比喻成“西医”,那“机器学习”就有点像“中医”。二者的区别是:作为人类经验的总结,中医更关心某个“偏方”或治疗方案是否有效,却不需要知道它为什么有效;与中医不同的是,西医的每一步进展都要建立在严密的逻辑推理和临床实验的基础上的。
从应用场景来看,简约式估计、机器学习方法也可以用于从经济数据到假说的“信息提炼”阶段,而结构式估计则只能在我们对变量时间的关系,即明白了“为什么”的问题之后,才能进行量化分析。不管依赖简约式估计还是结构式估计,如果我们无法解释所得到的相关关系背后的传导机制时,我们是无法依靠它们做决定的。
在很多时候,忽略变量的因果关系和传导机制可能是致命的。例如,在工业系统中的应用除了对精度有非常苛刻的要求外,还需要解释预测结果的合理性,以及相关的不确定性风险,而只有了解不确定性存在的原因,才能够用其他辅助手段对其进行管理。否则的话,即便是发现了变量之间的相关关系,我们也没有办法根据分析结果进行决策。从这个角度来看,“中医”和“西医”的比喻则是不恰当的。因为,高明的医生不是完全根据症状来决定开什么处方,而是要根据病症之后的隐藏信息来决定治疗方案。这也是名医和庸医的本质区别。
据《三国志·魏志·华佗传》记载:东汉末年,有个州官叫倪寻的。有一次,他和李延一起到名医华佗那儿看病。他们两个人都是头痛发热,所受的痛苦也完全一样。华佗看了两个人的病后说:“倪寻要用泻药,李延则要吃发汗的药。”他们听了觉得奇怪,就问:“病情一样,用药为什么不同呢?”华佗答道:“倪寻的身体外部很壮实,没什么毛病,只是内部有问题,而李延的体内没问题,病是由外部风寒引起的。所以,病情并不一样,治疗办法当然应该不同。”华佗随即分别给了不同的药,服后第二天,他们的病都好了。
2. 简约式与结构式估计的区别
在实际应用中,人们可能更容易混淆结构式估计和简约式的区别。为此,本节在接下来的分析中重点对二者的差别进行介绍。具体地,结构式估计和简约式估计的不同主要体现在以下方面:
(1)目的
简约式估计的重点是研究已经发生的事件,并确立变量之间的因果关系,即X是否对Y有“因果性的影响”(Causal effect)。在这里,“因果性”是与“相关性”相对应的。我们知道,如果把世界上任意两个变量放在统计和计量软件中都有可能发现二者是“相关的”。但相关性并不代表因果性。把二者混淆不仅可能产生令人啼笑皆非的结论,甚至可能误导政策制定。
与简约式估计不同的是,结构式估计则更试图更为准确地度量X对Y的定量影响。请注意,我不是说简约估计不看重变量之间的定量关系。只是说,结构式估计试图通过X对Y的影响机制,从而更为准确地刻画X的Y的影响。很多时候,采用简约式估计可能发现X对Y地影响微乎其微,但是实际上,只是因为在估计过程没有找到合适的对照组而言。特别是对于国际贸易和空间经济问题,产业关联和人口流动会导致任何一项地区或产业层面的政策都可能在全局产生“涟漪效应”,这就违背了简约式估计的基本假设。
此外,结构式估计不仅可以评估已经发生的事件,还可以用于评估尚未发生的事件可能带来怎样的影响,即回答“如果”的问题。

图4 童话故事中的“因果推断”
《不一样的卡梅拉》这套书中有一个叫做“我去找回太阳”的故事。在这个故事中,卡梅利多和卡门是鸡舍的两只小火鸡,每天都过着开心的日子。他们的爸爸火鸡皮迪克每天用自己高昂的嗓音唤醒太阳。在小火鸡们的眼中,皮迪克是一个可以指挥太阳的男子汉。小火鸡们羡慕、佩服、崇拜皮迪克。直到有一天,大地出现了连阴雨,皮迪克再也唤不醒太阳。小火鸡们立刻想造反了。他们认为皮迪克老了,不再能指挥太阳。梅利多和卡门不能忍受别人质疑自己爸爸的权威,于是踏上的寻找太阳的旅程。
你或许以为上面只是一个童话故事,然而现实中的很多人常常在不知不觉之间就犯了类似的错误。比如,有人看到房价上涨的同时看到盖房子的人数量增加了,于是就提出建议:为了控制房价,应该禁止盖房子。岂不知,如果没有供给,房价会上涨的更凶吗?!
(2)研究方法
由于简约式估计的重点是研究变量之间的因果性,因此,研究过程的中心在于处理变量的“内生性问题”。处理内生性的问题包括随机试验、拟自然试验、控制函数法和工具变量法等。简约式估计过程主要涉及试验设计和假设检验,并不需要基于理论建模。而结构式估计则是以理论建模为基础的,即必须从假设设定开始,经过一步步的数学推导,得出可以被验证的待估方程。
(3)传导机制
简约式估计的重点是确立变量之间的因果性影响。而结构式估计则必须要理解两个变量之间的传导机制,否则就无法估计出模型的参数。国内对于简约式估计通常存在两种误区:一种误区认为,做简约式估计是不需要理解传导机制的,不管三七二十一,只要能跑出回归结果就行。还有一种误区是误把理解传导机制等同于进行机制检验。很多时候,或许我们理解了变量的传导机制,但是多数情况下还是难以进行机制检验。这两种错误的做法都不可取,前者的错误是显而易见的,因此,容易辨别。而后者的错误就不那么容易辨别了,因此,也导致采用简约式估计的文章存在鱼目混珠的现象。
所谓“机制检验”,是指要确认X(解释变量)会通过Z(传导变量)来影响Y(被解释变量),而且Z是X影响Y的主要渠道。进行“机制检验”有两大难点:其一是这样的Z(传导变量)很多,怎样才能找到最重要的Z呢?其二,如果你找到了很多这样的Z,你怎样能说服读者,X对每一个Z的影响是“因果关系”而不是“相关关系”呢?
第一个难点的关键其实与计量方法无关。要找到这样的Z很多时候依靠的是经验或经济学理论。因此,缺乏社会经验和良好经济学理论训练的人是很难找到这样的传导变量的。
第二个难点在于要说服读者:“从X到Z”和“从Z到Y”这两个步骤都是“因果性关系”而不是“相关性关系”。从数学上看,处理二个变量的关系是个“一维”问题,而处理X、Z、Y这三个变量的关系则变成了“三维”问题。而一旦这样的Z的数目变为,问题的维度就会上升至。其中的“”代表X对Y对影响,是因为对于每一个中介变量,都涉及到两组关系(即其与X和Y的关系)。
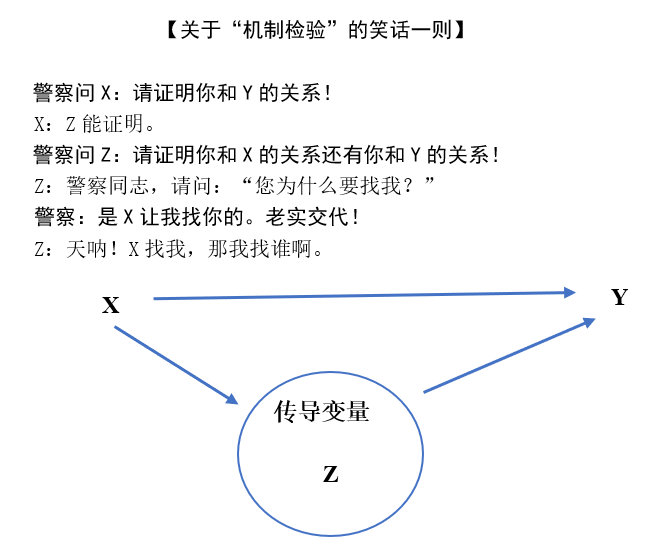
图5 “机制检验”的困难
实际上,很多发在顶级期刊上的论文无非是成功处理了两个变量之间的内生性问题。处理内生性的难度由此可见一斑。如果我们连“一维”的问题就解决不了,那么又怎么解决“三维”或者“更高维”的问题呢?
故此,机制检验近似于一个不可能完成的任务。如果所有进行简约式估计的论文都要求进行机制检验,那由此带来的后果就是“灌水”。明知不可为而偏要为之或者强迫别人为之,那就只能逼出谎言来。这样的例子自古以来就不新鲜。明明知道人不可能成为圣人,却要求人人都成圣的结果就是造就一个个的伪君子。
在简约式估计中,如果找不到变量之间的传导机制,那么一篇论文仍然有可能会被发表。但是对于结构式估计而言,如果不知道变量的传导机制,那么可能连参数都估计不出来。这是为什么很多同学在参加了结构式估计的培训之后依然写不出结构式估计的论文的关键。因为在短期培训中,培训老师只能把讲解的重点放在如何进行代码实现上。但殊不知,编写代码只是结构式估计的一个环节而已,而且还不是最重要的环节。
当然,这不是说做简约式估计不需要思考变量的传导机制。无论是简约式估计还是结构式估计,都需要作者对变量的传导机制有深入的思考,否则就真的与机器无异了。只是要想学会结构式估计,首先就需要学会理解理论模型的传导机制。而这个过程,只能通过经济学理论训练才能获得。除此之外,别无他途。之所以通过短期培训无法获得理论思维的关键并不在于时间太短,而是参加短期培训的多数人的心无法安静下来。因为理论思维的训练需要排除一切外在干扰,并让让大脑达到轻松、愉悦和享受的状态。为了达到这个状态,我们需要抛下一切目标,把注意力单单聚焦于理论本身。因此,学会了沉静,理论思维能力可以很快学会。但如果心浮气躁,经济学理论思维能力永远也不可能得到。在信息超载的时代,沉静似乎越来越困难,也越来越显得宝贵。
(4)浅层参数与深层参数
这个区别与“卢卡斯批评”(Lucas Critique)有关。“卢卡斯批评”说的是,永远不要基于历史数据的研究结果来预测未来,因为基于历史数据所估计出来的参数并不是一成不变的,是浅层参数(shallow parameter)。例如,我们不能根据中国加入WTO对中国企业生产率的影响来推断中国加入RCEP(Regional Comprehensive Economic Partnership的简称)会带来怎样的影响。不同的政策在不同的历史阶段对不同的国家可能会产生截然不同的结果。而结构式估计之所以能够对尚未发生的政策进行政策评估是因为,结构式估计所估计的参数并不是“浅层参数”,而是所谓的“深层参数”或“行为参数”。所谓的“深层参数”,是指这些参数是一些比较稳定的、不受政策影响的变量。当然,稳定是相对的,绝对的稳定的变量可能是不存在的。所以,结构式估计的艺术在于根据所研究的问题,确定哪些参数是“深层参数”,然后进行理论建模。
(5)估计系数的偏误






注:这个部分的分析参考了周默涵(2023)“以一般均衡的视角审视简约式实证研究”这篇微信公众号的推文。
(7)简约式估计存在的其他问题
本节重点就关于简约式估计的一些常见问题和大家分享。然而在之前,必须声明的一点是:我在这一节重点对简约式估计的误用进行批评,并不是说采用简约式估计就一定不如理论建模或结构式估计;而是因为在实际应用中或许是简约式估计上手的门槛比较低,所以“滥用”、“误用”的问题比较严重而已。
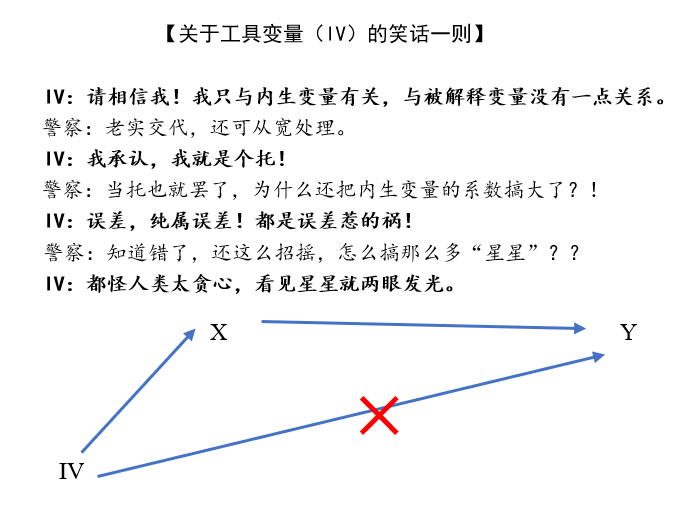
图7“工具变量”的陷阱
第一个问题是:用“工具变量”来解决内生性问题。关于工具变量的计量理论本身是没有问题的,问题是很多文章把工具变量当成万能公式来套用。现实中,大家对“工具变量”的误用主要体现在两个方面:其一是,用一个“工具变量”来解决多个变量的内生性问题。比如,在一篇文章中,采用地理变量作为制度的“工具变量”;而在另一篇文章中,采用地理变量作为“人力资本”的工具变量。这就和“工具变量”的本义相矛盾了。计量理论告诉我们,有效的工具变量需要满足“相关性”和“外生性”两个条件。如果一个变量可以对多个变量产生影响,这门这个变量很明显不满足“外生性”假设。当然了,这里的“外生性”与变量是不是“外生的”没有必然的联系。地理变量虽然独立于人类而存在,但依然可能存在内生性问题。
其二是动辄用一阶或者二阶滞后项来解决变量内生性问题。这种做法实在是过于“粗暴”,是实在找不到“工具变量”情况下的无奈之举。不是说不可以用滞后项来解决变量内生性问题,问题在于,不是所有的内生性都可以通过取滞后项就能够解决的。比如,很多变量在时间上是存在连续性的,滞后项与当前的变量取值不可能没有关系,也常常与残差项中遗漏的变量相关。
第二个问题其实是一个误解,认为所有的内生性都是可以解决的。现实中有很多问题的内生性是无法解决的,但是这并不意味着我们可以忽略这些问题。不妨考虑下面的例子:
案例:搜集1980-2000年发表在Journal of International Economics的论文,生成两个变量:CES和MP。其中,CES和MP均为虚拟变量。具体地,若该论文采用了CES效用函数,则CES=1,否则CES=0。MP为假定市场结构为垄断竞争的虚拟变量。以CES为被解释变量对MP回归不难发现,二者成显著的正相关关系。也就是说,假定垄断竞争的文献通常会采用CES效用函数。但是,CES效用函数和垄断竞争的市场结构之间没有必然联系。CES效用函数对于垄断竞争而言既非充分,也不必要。
在这个案例中,这个计量回归存在严重的内生性问题,而且该内生性问题是无法采用计量方法来解决的。此时,计量经济学方法是失效的。为了判断二者的关系,我们只能依靠经济理论。
现在,有越来越多的程序包可以做简约式估计。在不久的将来,简约式估计最需要的工作不再是写代码,而是寻找数据和政策冲击,或者自己做社会实验。然而,令人遗憾的是,需求并不会自动创造供给。因为学者的需求并不能在当期立即产生社会价值,而且与商业价值相比,研究所产生的知识是“非排他性”、“非竞争性”且具有很大的“不确定性”。特别是对于社会科学而言,很多研究成果的社会价值可能要几十年,或者上百年后才可能显现出来。面对遥遥无期的不确定收益(而且还落不到自己头上),似乎还是抓住现在比较明智。
最后,我们不能依据一篇论文究竟是应用了简约式估计还是结构式估计来判断这篇论文的好坏。所谓“功力有深浅,技法无高低”。一篇完全不用数理模型、结构式估计或简约估计方法的论文一样可以写得很精彩。在武侠小说《射雕英雄传》中,郭靖只凭借一招“亢龙有悔”便打得梁子翁招架不住,也就是这个道理。
如果把简约式估计和结构式分别比作刀和枪,它们应该都是很好的工具,都对我们认识世界和改造世界有帮助。刀有刀的优势(短板),枪有枪的优势(短板)。我们应该针对研究的目标,选择最适用的工具。无论是刀还是枪,用的好坏,取决于用的人对于工具和研究目的的了解程度。无论是哪种方法,用得好的都是高手、都是极少数。
因此,刀和枪在未来的经济学研究中应该是高度互补的,因为两种各有所长但又各自受限。如果我们的目的是打一个猎物让人们更好地存活的话,最好的办法是,用枪来打猎物,然后用刀子进行“庖丁解牛”。[1] 而把这些不同的工具有效组合起来的方法就是经济学理论。
[1] 感谢中国人民大学刘瑞明教授提供这个比喻。
第五节 总结
“信息数字化”和“智能化”是数字技术革命区别于蒸汽革命、电力革命和信息技术革命的关键差别。虽然,从第三次技术革命(即信息技术革命)开始,计算机就已经开始把人类从一部分的数据分析和计算中解放出来。但总体而言,计算机所从事的主要是一些简单的“信息处理”。与第三次技术革命所不同的是,数字技术革命的到来导致越来越多的复杂任务可以交给机器人和人工智能来完成。他们不惧危险,不需要休息,而且也比较廉价。对此,一部分人认为:由于人工智能可以自我学习,因此,未来有一天人工智能可能会代替人类所有的工作。对于研究人员而言,经济学家也可能在人工智能面前不堪一击;还有一部分人则非常乐观。他们认为,随着大数据时代的带来,未来会出现大量的研究数据。为此,应该更多地学习机器学习方法,否则,未来很可能丧失做研究的先机。本文认为,这两种观点都失之偏颇。具体地,本文认为:
第一, 在数字经济时代,大数据的技术属性决定了大多数面对的并不是“数据爆炸”,而是“数据荒漠”。因此,把时间、精力孤注一掷在数据分析和统计学习方法上,有可能与学习“屠龙术”无异。
第二, 过去二十年的贸易理论告诉我们的一个重要研究结论是:如果所有人都预期某个行业由大好的前途,那么最终的结果就是这个行业会变得越来越“卷”,生存会越来越困难。因此,明智的做法是另辟蹊径,而不是随波逐流。
第三, 经济学研究会越来越多的依靠理论和灵感,这正是AI所不具备的能力。AI会帮助我们做简单的数据分析、公式编辑、图表分析,甚至帮我们编写代码,而原创性的工作最终只能交给人来做。经济学者们则需要沉静下来,不被世俗所扰,才能真正做出原创性的研究。“信息超载”越严重,沉静的价值就越宝贵。
经济、社会经历剧烈的结构性调整的时候也正是进行经济学理论创新的良机。在这个过程中,形形色色的数据、政策和制度冲击以及经济现象会错综复杂地交织在一起。我们需要立足时代,根据研究问题的需要来选择研究方法,而不是被具体的研究方法所牵制。机器学习、简约式估计和结构式估计都是人类从经济现象中提取“信息代码”的重要方式,但是却不一定是最主要的方式。这些方法各有侧重,最有效的方式是用人脑的智慧把它们有机结合在一起。
编辑:冯双婷 程一然
审校:彭支伟
2023年12月28日