云鹰读书会2024第47期(总第231期)
2024-11-27特别鸣谢
本次云鹰读书会由南开大学国际经济贸易系
系友苏武康博士赞助支持
摘要
需求函数的估计是最近许多研究的核心,这些研究探讨了差异化产品市场中企业市场势力、企业兼并、创新和新品牌估值等问题。本文重点介绍了估计差异化产品需求函数的主要方法之一:随机系数离散选择模型,并详细阐述了这一方法的模型设定、估计过程以提高研究人员对该方法的理解,降低使用这些方法的难度,从而帮助充分发挥这些方法的潜力。其创新之处体现在:第一,工具变量的引入可以有效解决价格内生性问题,使需求函数的估计更为准确。第二,需求弹性以及产品间的替代弹性不再是外生给定的。
目录
一、 引言
二、 模型
三、 估计
四、 应用
五、 总结
1. 引言
对需求的估计一直是最近许多研究的关键部分。对于一组密切相关但不完全相同的产品,最直接的指定需求的方法可能是指定一个需求方程系统。每个方程都将一种产品的需求指定为其自身价格、其他产品价格和其他变量的函数。这种系统的一个例子是线性支出模型(Stone,1954)。随后的工作集中在以一种既灵活(允许一般替代模式)又与经济理论一致的方式指定价格与数量之间的关系。
估计差异化产品的需求增加了两个额外的重要问题。第一个是大量的产品,因此需要估计大量的参数。即使我们施加经济理论所隐含的对称和其他限制,参数的数量仍然过大而无法估计。如果我们允许更加一般的替代模式,这个问题将会更加严重。另一个问题是消费者tastes的异质性:如果所有消费者都是相同的,那么我们就不会观察到在市场上看到的差异化水平。研究者可以假设偏好具有正确的形式,因此总体或平均消费者存在,并且具有满足经济理论条件的函数。然而,这需要很强的假设,且对于许多应用而言,这种假设在经验上是错误的。总体和明确反映个体异质性的模型间的差异可能对经济和政策结论产生深远影响。
Logit需求模型(McFadden,1973)通过将产品投射到特征空间解决维度性问题。logit需求模型使产品的特征成为该空间的维度,而不是产品数量的平方。但logit需求模型的一个问题是由于异质性建模的限制性方式,产品之间的替代完全由市场份额驱动,而不是由产品的相似程度驱动。
基本Logit模型的扩展放宽了这些限制性假设,同时保持了logit模型在处理维度问题上的优势。其基本思想是明确地对总体中的异质性进行建模,并估计控制这种异质性分布的未知参数。这些模型已经使用市场和个体层面的数据进行估计。估计中的问题在于它将包括价格在内的回归量都看看作生决定的。当使用总体数据来估计模型时,这尤其成问题。
本文描述了需求随机系数离散选择模型估计方法的最新进展[Berry,1994;Berry et al.,1995(henceforth BLP)]。BLP保持了logit模型在处理大量产品时的优势。但它又优于先前的方法,因为(1)该模型可以仅使用市场层面的价格和数量数据进行估计;(2)处理了价格内生性问题;(3)它产生了更为现实的需求弹性。
2. 模型





3. 估计






4. 应用
使用的数据来自即食食品行业,数据包括47个城市超过2个季度的24个品牌差异化产品的数量和价格,使用了两个产品特性:Sugar(测量糖含量)和Mushy(如果产品在牛奶中变湿,则等于1的虚拟变量)。人口统计数据来源于当前人口调查(Current Population Survey)。它们包括收⼊对数(income)、收⼊平方对数(incomeSq)、年龄和儿童(如果小于16岁,则为1的虚拟变量)。未观察到的人口统计数据是从标准正态分布中抽取的。对于每个市场绘制了20个个体[即公式(11)中的ns=20]。
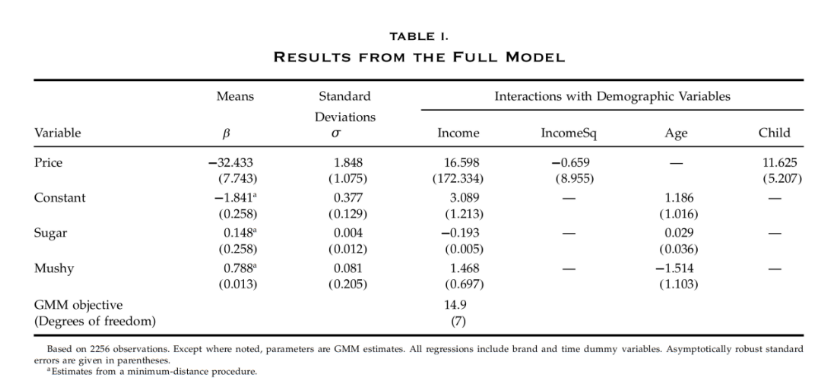
在表1中,边际效用的分布的均值是通过上面描述的最小距离程序估计的,并在第一列中给出。结果表明,对于普通消费者来说,糖越多,产品的效用就越高。在接下来的几列中给出了对这些均值的异质性估计。标记为“标准差”的一栏捕获了未观察到的随机因素的影响。
Mushy的边际估值会随着年龄和收入的增加而降低。换句话说,成年⼈对麦片的脆度不那么敏感,富裕的消费者也是如此。Mushy系数的分布如图1所示。大多数消费者对湿性的评价是积极的,但大约31%的消费者实际上更喜欢脆脆的麦片。
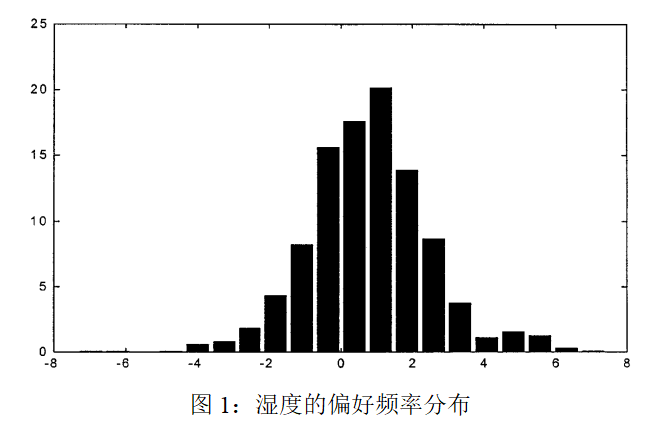
平均价格系数为负,价格与人口统计学相互作用的系数在经济上是显著的,儿童和收入高于平均水平的消费者往往对价格不那么敏感。个体价格敏感性的分布如图2所示。它似乎不是正态分布,这是人口统计学经验分布的结果。原则上,分布的尾部可以达到正值——这意味着价格越高,效用越高。然而这些结果并非如此。
所有标准差的估计值在经济上都不显著,表明系数的异质性主要由纳入的人口统计数据来解释。衡量人口统计和随机冲击的相对重要性,可以从人口统计解释的方差与估计系数分布中总变异的比率中获得,都在90%以上。这个结果与以前有些不一致。这里的结果并不表明观察到的人口统计学可以解释所有的异质性;它们只表明数据拒绝了假设的正态分布。
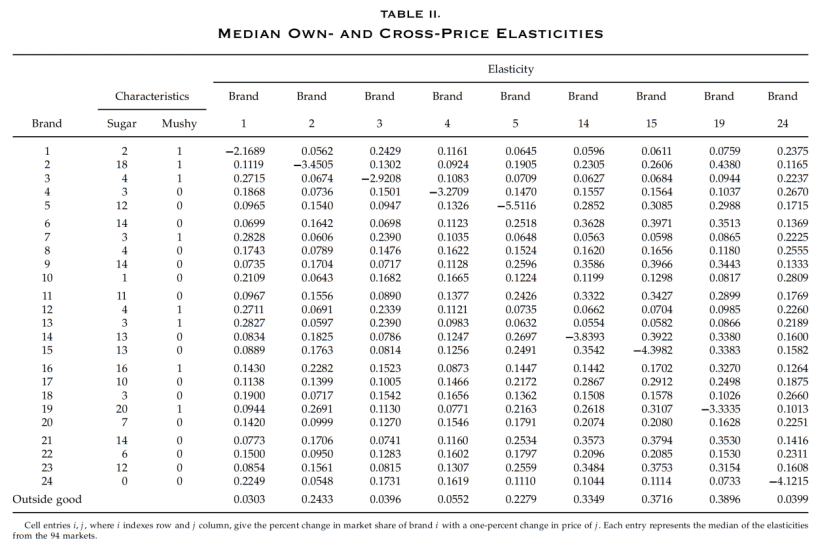
每个条目i,j,其中i索引行,j索引列,表2给出品牌i相对于j价格变化的弹性。由于该模型并不意味着弹性恒定,因此该矩阵将取决于用来评估它的变量的值。结果展示了在这个模型中替代模式是如何确定的。在其他条件相同的情况下,具有相似特征的产品将具有更大的替代模式。模型克服这些限制的程度的一个指标是检查估计弹性的变化。一种这样的测量方法是通过检查列内最大与最小交叉价格弹性的比率来给出的(logit模型意味着列内所有交叉价格弹性相等,因此比率为1)。这个比值从9到3不等,告诉我们结果已经克服了logit限制,还提示了哪些品牌的特征似乎不足以克服限制。
5.总结
本文系统介绍了随机系数离散选择模型,其优点表现为:第一,自身价格弹性由购买各种产品的消费者之间价格敏感性驱动。第二,模型允许不受市场先验细分约束的灵活替代模式。第三,随机系数logit模型处理了价格内生性问题。但这一方法也存在不足之处:首先,积分得到的市场份额不再有解析封闭形式,难以计算结果。其次,需要关于消费者异质性分布的信息来计算市场份额。
参考文献
[1] Aviv Nevo. “A Practitioner’s Guide to Estimation of Random-Coefficients Logit Models of Demand,”. Journal of Economics & Management Strategy, 2000, Volume9, Number4, Winter2000, 513-548.
文稿:刘灿 周柯男
编辑:吕宸慧
审校:冯笑
2024年11月27日